


















百度文档是一款百度文档下载器,最近用百度文库里面的word文档,每个都要下载券,搞得火大。到网上搜索,可以下载原格式的,都是需要千方百计的要付费。唯一几个不需要付费的,下载下来格式惨不忍睹,几乎都不能用,只是单纯的txt文本,还没有什么换行。
软件说明
1:不能下载付费文档。 也就是需要付人民币的,都不行。
2:其实说白了,就是把可以预览的word部分给整理出来,变成doc格式。
3:如果word里面都是图片的。已经遇到过这种情况了,现在还不能支持。是不是图片,用鼠标在百度文库页面划拉一下就知道了,不能被选中的就是图片。
功能特色
为啥不用冰点文库?
主要是因为冰点是先导出pdf,然后扫描出txt,文字识别有可能会错误,还有就是用word打开txt文档还是有字体,颜色等丢失,pdf本身编辑又不方便。还有就是总是要设置我的首页。。。。。
特意做了这样的一个小工具,共享给大家。有很多地方还可以继续优化,可是做的非常累,给大家看看有没有人喜欢,有人喜欢的话,偶就继续再做做。
偶本身不是做界面出身的,因为要给大家使用,还强行去学了一个界面,搞得丑的自己都不想要,大家克服一下吧。
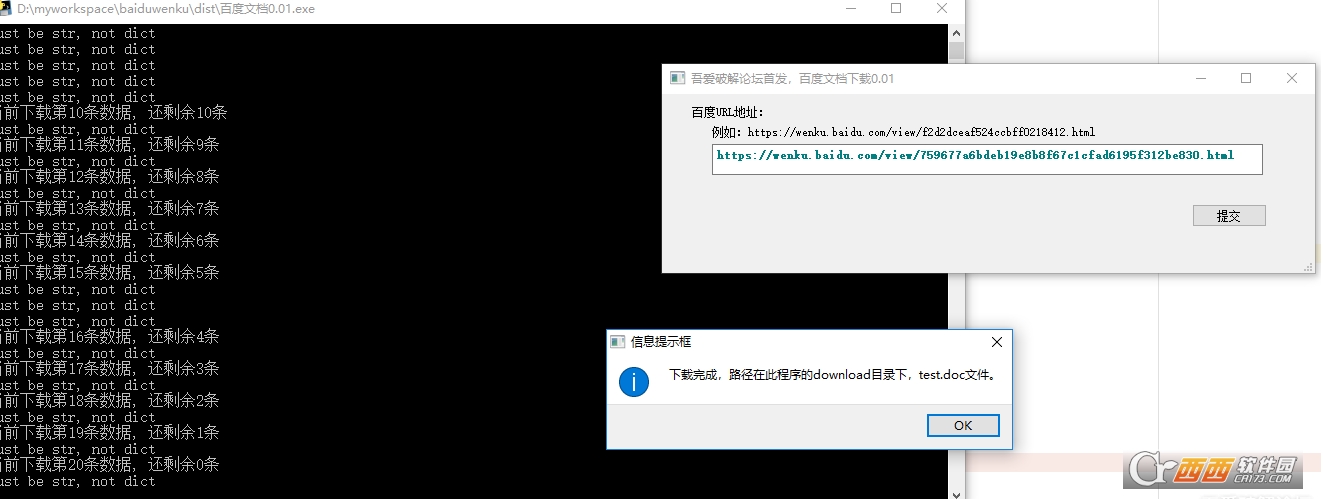
界面逻辑,就一个按钮(实在是不会写界面),空白框里面输入百度文库地址,点击提交。
文档下载到当前目录下的download文件夹里面,无论啥文件,下载号以后都叫test.doc,自己注意重命名,不然会覆盖。 (下个版本加上自动命名吧)
还有就是偶用python做的,不知道为啥python3.7打包出来文件好大好大,要37.6MB,我也很崩溃呀,如果是我自己看到这样的大小,我也以为是病毒呀,可是确实就是这么大,这里面没有任何广告,后门 。。。。。
界面后面故意留了个command窗口,是因为不会做进度条,下载时有信息都是直接输出到command窗口的。大家要是不希望回头我去学怎么做个进度条出来。。。。
当前可以做到的是:
1:仅仅支持DOC格式,虽然pdf,txt格式不难,但是还没有时间去做。
2:这个工具可以做到的就是doc文件格式文本下载,字体,颜色,段落基本上都是正确的。
3:目前只能撷取doc文章中的文字部分,图片部分当前还没有完成,已经有思路了,技术上是可行的,回头我再想想怎么整合到代码里面去。
当前实现功能
1:doc格式可以下载,可以识别部分:
1.1:硬回车换行,基本可以正常识别。
1.2:表格中偶尔有硬回车,基本可以识别。
1.3:软回车,基本可以识别
2:文字应该不会有错别字,因为不是用pdf扫描识别做的。


 大小: 122.8M
大小: 122.8M





 大小: 90.4M
大小: 90.4M Adobe Application Manager10.0 官方最新版
Adobe Application Manager10.0 官方最新版  迅雷极速版v1.0.35.366 绿色精简版
迅雷极速版v1.0.35.366 绿色精简版  迅雷7(集成本地Vip)v7.9.44.5056 去广告精简绿色版
迅雷7(集成本地Vip)v7.9.44.5056 去广告精简绿色版  FLV网络视频嗅探器(FlvCapture)0.3 绿色版
FLV网络视频嗅探器(FlvCapture)0.3 绿色版  foxy繁体V1.98 绿色免费版
foxy繁体V1.98 绿色免费版  迅雷5(Thunder)V5.9.28.1564 官方正式版
迅雷5(Thunder)V5.9.28.1564 官方正式版  uTorrentv3.5.5.46552 官方正式版
uTorrentv3.5.5.46552 官方正式版  115网盘客户端v8.2.0.45 官方安装版
115网盘客户端v8.2.0.45 官方安装版  盛大下载器2016v1.9.0.6 官方稳定版
盛大下载器2016v1.9.0.6 官方稳定版  步步高点读机下载工具V2.1.0 官方最新版
步步高点读机下载工具V2.1.0 官方最新版  硕鼠20180.4.8.1 官方最新版
硕鼠20180.4.8.1 官方最新版  维棠FLV视频下载工具v3.0.1.0 官方正式版
维棠FLV视频下载工具v3.0.1.0 官方正式版  QQ旋风2014v4.5.760.400
QQ旋风2014v4.5.760.400  Internet Download Manager(IDM)V6.35.3中文精简版
Internet Download Manager(IDM)V6.35.3中文精简版  快车、迅雷、QQ旋风、FS2You、RayFile、纳米盘等链接转换器V1.0 绿色离线版
快车、迅雷、QQ旋风、FS2You、RayFile、纳米盘等链接转换器V1.0 绿色离线版  MTV分享精灵20151.5.1 绿色免费版
MTV分享精灵20151.5.1 绿色免费版  比特精灵(BitSpirit)V3.6.0.500 免费简体中文绿色版
比特精灵(BitSpirit)V3.6.0.500 免费简体中文绿色版  QQ旋风4.5(757) 绿色版
QQ旋风4.5(757) 绿色版