

















网站DNA帮助文档:
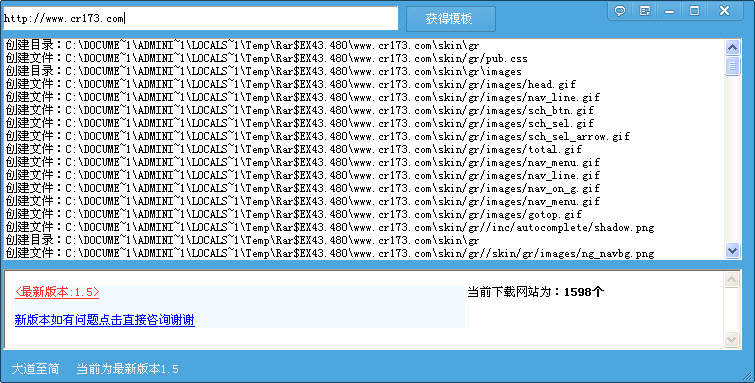
1、第一步选择需要下载的网页,一般只要网站首页 例如:http://www.cr173.com/
因为其他页面调用页面CSS样式文件和JS文件可能包含在首页里面,所以其他页面可能只要复制页面代码 存2张图片即可!
点击下载按钮,此时可能会卡住、不用当心 等网站下载完成后会自动恢复!
只能下载模板,网站后台下载任何软件可能也做不到!
建议用服务器测试网站,下载的网站目录结构清晰下载效果更好!试用效果后在进行评价!程序会一直免费,一直更新最完善的版本!
对网站内容下载有js,CSS,CSS文件内部图片,src图片,背景图片,表格框架图片,深层目录!
版本1.7 2012/09/11 更新说明
增加多线程处理,解决程序卡主问题,模板下载更快!
修复部分下载模板需要开启服务器才能正常访问,目前直接打开访问即可!
增加对flv文件的下载。
解决一部分小问题!
版本1.8 2012/09/12 更新说明
增加对淘宝和天猫的特殊CSS,JS结构处理,完美支持对淘宝天猫商城的模板扒皮,绝对网络唯独一款可以扒皮淘宝天猫模板的!
增强对子目录扒皮的优化!
解决一部分小问题!
版本1.9 2012/09/16 更新
修复一小部分BUG,
增加SEO功能
版本2.1 2012/10/10 更新
1.9之后的版本不能下载淘宝模板,以后增加!
2012/09/08 临时通宵更新说明
对带参数CSS 以及JS无法获取的修复
对远程链接都能一一下载,远程链接自动改为本地链接
与../以及../../的处理
更新皮肤界面
修复若干问题,以及对论坛模板下载的优化
下个版本将推出更多功能、以及使用说明文件如何利用本工具快速获取网站模板!

 大小: 57.8M
大小: 57.8M

 刷PV工具(刷网站点击量)v1.0.0.1绿色版
刷PV工具(刷网站点击量)v1.0.0.1绿色版  流量宝V2.3.1423 绿色免费版
流量宝V2.3.1423 绿色免费版  流量神器v2.0.1.0 免费版
流量神器v2.0.1.0 免费版  windows2003 64位 iis安装包完整版
windows2003 64位 iis安装包完整版  xamppsv8.1.2 最新版【x64】
xamppsv8.1.2 最新版【x64】  apache tomcat8.5.20 官方版【x86x64】
apache tomcat8.5.20 官方版【x86x64】  网站抓取精灵3.1.0.0 正式版
网站抓取精灵3.1.0.0 正式版  飞达鲁长尾词查询工具V2.9.13.263 中文绿色版
飞达鲁长尾词查询工具V2.9.13.263 中文绿色版  本地PHP服务器MiniServer(迷你WAMP)v1.2 绿色版
本地PHP服务器MiniServer(迷你WAMP)v1.2 绿色版  网页截图扩展(Webpage Screenshot)5.4.9.9 chrome
网页截图扩展(Webpage Screenshot)5.4.9.9 chrome  Simon爱站关键词采集工具4.0 无限制免费版
Simon爱站关键词采集工具4.0 无限制免费版  google 工具条全新版6.4.1321.1732
google 工具条全新版6.4.1321.1732  Apache Tomcatv10.0.10 官方版
Apache Tomcatv10.0.10 官方版  域名批量查询(Domain Name Analyzer Pro)v4.5 英文绿色特别版
域名批量查询(Domain Name Analyzer Pro)v4.5 英文绿色特别版  hao
hao
