











python爬取138看书网小说源码,来自论坛大神原创制作的一个爬取源码,可以帮您爬取138小说网的小说资源,支持分类搜索查找功能,支持目录爬取,自带书签系统,让您看小说更加轻松。本次带来python爬取138看书网小说源码资源下载,需要看小说的朋友们不妨试试吧!

python爬取138看书网小说源码作者说明
记录一下今天爬的第二个小说网,第二次弄起来比较熟练了,不像第一次弄一半就得找教程边看边搞。
但实际上爬小说应该是最简单的事情了吧,涉及的技术也没有那么深。
把代码发出来让想刚入门却不知道从何下手的同萌新们看看吧,看教程总是云里雾里的,还是还得上手多练练才能加深印象。
这个小说爬虫还是有点垃圾,多线程没有,而且有些函数也是用的跟*一样,这玩意该怎么改进也没有头绪。
python爬取138看书网小说源码演示一览
import requests
import lxml
import re
headers = {
'user-agent': 'User-AgentMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
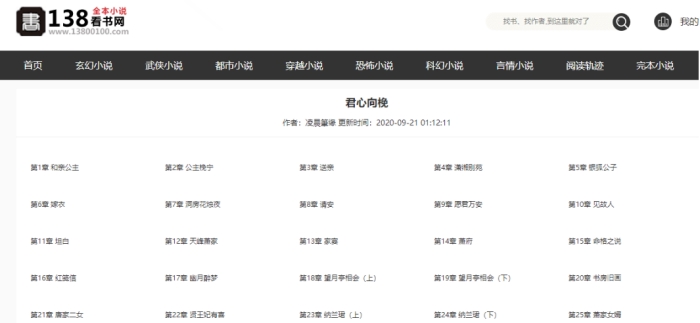
print ('本脚本仅适用于138看书网:https://www.13800100.com/')
#url_list = 'https://www.13800100.com/list/72262/'
url_list = (input('粘贴小说目录url,必须是小说目录,小说首页不支持\n'))
downurl = 'https://www.13800100.com/article/'
url_list = requests.get(url_list)
text_list = url_list.text
#爬小说书名
text_title = re.findall(r'<div class="cate-tit">(.*?)</h2>',text_list,re.S)[0]
text_title = text_title.replace('\r\n','')
text_title = text_title.replace('<h2>','')
text_title = text_title.replace(' ','')
#爬小说目录列表
text_list_info = re.findall(r'<div class="bd">.*?</div>',text_list,re.S)[0]
text_list_info = re.findall(r'<a href="/article/(.*?)" class="name">(.*?)</a>',text_list)
for i in text_list_info:
#每章小说的url和每章章名
list = i[0]
name = i[1]
download = downurl + list
download_info = requests.get(url = download,headers=headers)
html=download_info.text
html_info = re.findall(r'<div class=".*?">(.*?)</div>',html,re.S)[0]
html_info = html_info.replace (' ','')
html_info = html_info.replace ('<br/>',('\n'))
html_info = html_info.replace (' ','')
print (name)
#输出为记事本
with open ('%s.txt' % text_title,'a+',encoding = 'utf-8')as f:
f.write(' '+ name + '\n')
f.write('\n')
f.write(html_info + '\n')
f.write('\n')
print ('下载完成')

 大小: 109KB
大小: 109KB

 大小: 110.6M
大小: 110.6M PHP和MySQL Web开发第4版源代码
PHP和MySQL Web开发第4版源代码  SSH框架整合小案例
SSH框架整合小案例  51单片机150个例程
51单片机150个例程  PHP操作excel类(PHPExcel)1.7.7
PHP操作excel类(PHPExcel)1.7.7  逐梦旅程:Windows游戏编程之从零开始 配套源代码
逐梦旅程:Windows游戏编程之从零开始 配套源代码  HTML 5开发精要与实例详解 配套源码
HTML 5开发精要与实例详解 配套源码  HTML-CSS-JavaScript标准教程实例版
HTML-CSS-JavaScript标准教程实例版  c语言经典编程900例
c语言经典编程900例  C# 教务管理系统源码
C# 教务管理系统源码  C++Builder学习大全中文版
C++Builder学习大全中文版