U大师v4.7.37.56 最新版
U大师v4.7.37.56 最新版 HD Tune Prov5.75 汉化绿色特别版
HD Tune Prov5.75 汉化绿色特别版 DiskGenius 专业版V5.2.1.941 官方版
DiskGenius 专业版V5.2.1.941 官方版 360软件管家v7.5.0.1460 官方最新版
360软件管家v7.5.0.1460 官方最新版 Cpu-Z中文版v1.98.0 绿色中文版
Cpu-Z中文版v1.98.0 绿色中文版 腾讯电脑管家V15.2 官方正式版
腾讯电脑管家V15.2 官方正式版 office2016激活工具kmsv19.5.2 官方最新版
office2016激活工具kmsv19.5.2 官方最新版 迅雷11最新版v11.3.6.1870 官方版
迅雷11最新版v11.3.6.1870 官方版 360免费wifi5.3.0.5000 官方最新版
360免费wifi5.3.0.5000 官方最新版 360安全浏览器2022v13.1.5188.0 官方正式版
360安全浏览器2022v13.1.5188.0 官方正式版 酷我音乐盒2022v9.1.6.2 官方正式版
酷我音乐盒2022v9.1.6.2 官方正式版 暴风影音2021V5.81.0202.1111官方正式版
暴风影音2021V5.81.0202.1111官方正式版 快播5.0永不升级版5.0.80 骨头版
快播5.0永不升级版5.0.80 骨头版 优酷2022客户端V8.0.9.11050 官方最新版
优酷2022客户端V8.0.9.11050 官方最新版 爱奇艺视频V13.1.5官方安卓版
爱奇艺视频V13.1.5官方安卓版 photoshop cs6 中文版13.1.2.3 免费中文版
photoshop cs6 中文版13.1.2.3 免费中文版![Autodesk 3ds Max 2012官方简体中文版[32&64]](https://p.e5n.com/up/2018-9/2018921055101508.png) Autodesk 3ds Max 2012官方简体中文版[32&64]
Autodesk 3ds Max 2012官方简体中文版[32&64] CAD2007免费中文版
CAD2007免费中文版 vc运行库2019最新版v2019.3.2(32&64位)
vc运行库2019最新版v2019.3.2(32&64位) .NET Framework 4.8官方版4.8.3646
.NET Framework 4.8官方版4.8.3646 QQ2022v9.5.6.28129 官方最新版
QQ2022v9.5.6.28129 官方最新版 微信电脑版2022v3.5.0.44 官方正式版
微信电脑版2022v3.5.0.44 官方正式版 千牛卖家工作平台v9.02.02N 官方版
千牛卖家工作平台v9.02.02N 官方版 QT语音V4.6.80.18262官方最新版
QT语音V4.6.80.18262官方最新版 飞信2018V6.2.0700 官方正式版
飞信2018V6.2.0700 官方正式版 侠盗飞车罪恶都市
侠盗飞车罪恶都市 骑马与砍杀维京征服
骑马与砍杀维京征服 虐杀原形2
虐杀原形2 以撒的结合
以撒的结合 杀手5赦免
杀手5赦免 H1Z1中文版
H1Z1中文版 孤岛惊魂3
孤岛惊魂3 三角洲特种部队6战队之刃
三角洲特种部队6战队之刃 使命召唤8:现代战争3
使命召唤8:现代战争3 合金装备5:幻痛
合金装备5:幻痛 欧洲卡车模拟2
欧洲卡车模拟2 旋转轮胎
旋转轮胎 极品飞车18
极品飞车18 神力科莎
神力科莎 F1 2015
F1 2015 我的世界1.8.2
我的世界1.8.2 泰拉瑞亚
泰拉瑞亚 饥荒:海难
饥荒:海难 星界边境
星界边境 最后生还者PC版
最后生还者PC版 文明5:美丽新世界
文明5:美丽新世界 三国志12威力加强版
三国志12威力加强版 信长之野望14威力加强版
信长之野望14威力加强版 阿提拉:全面战争
阿提拉:全面战争 帝国时代2征服者
帝国时代2征服者 支付宝钱包(Alipay)V10.2.53.7000 安卓版
支付宝钱包(Alipay)V10.2.53.7000 安卓版 百度地图导航2022V15.12.10 安卓手机版
百度地图导航2022V15.12.10 安卓手机版 手机淘宝客户端v10.8.40官方最新版
手机淘宝客户端v10.8.40官方最新版 畅途网手机客户端v5.6.9 官方最新版
畅途网手机客户端v5.6.9 官方最新版 千聊知识服务appv4.5.1官方版
千聊知识服务appv4.5.1官方版 p2psearcher安卓版7.3 手机版
p2psearcher安卓版7.3 手机版 酷狗音乐2022官方版V11.0.8 官方安卓版
酷狗音乐2022官方版V11.0.8 官方安卓版 爱奇艺手机版v13.1.0
爱奇艺手机版v13.1.0 百度影音7.13.0 官方最新版
百度影音7.13.0 官方最新版 影音先锋v6.9.0 安卓手机版
影音先锋v6.9.0 安卓手机版 腾讯动漫V9.11.5 安卓版
腾讯动漫V9.11.5 安卓版 书旗小说免费版本v11.5.5.153 官方最新版
书旗小说免费版本v11.5.5.153 官方最新版 QQ阅读器appV7.7.1.910 官方最新版
QQ阅读器appV7.7.1.910 官方最新版 懒人畅听听书appv7.1.5 官方安卓版
懒人畅听听书appv7.1.5 官方安卓版 起点读书app新版本20227.9.186 安卓版
起点读书app新版本20227.9.186 安卓版 平安证券安e理财V9.1.0.1 官方安卓版
平安证券安e理财V9.1.0.1 官方安卓版 海通证券手机版(e海通财)8.71 官方安卓版
海通证券手机版(e海通财)8.71 官方安卓版 东海证券东海理财4.0.5 安卓版
东海证券东海理财4.0.5 安卓版 中银证券移动理财软件6.02.010 官方安卓版
中银证券移动理财软件6.02.010 官方安卓版 华龙证券小金手机理财软件3.2.4 安卓版
华龙证券小金手机理财软件3.2.4 安卓版 福建农村信用社手机银行客户端2.3.4 安卓版
福建农村信用社手机银行客户端2.3.4 安卓版 易制作视频剪辑app4.1.16安卓版
易制作视频剪辑app4.1.16安卓版 中国工商银行手机银行appV7.0.1.2.5 安卓版
中国工商银行手机银行appV7.0.1.2.5 安卓版 中国银行手机银行客户端7.2.5 官方安卓版
中国银行手机银行客户端7.2.5 官方安卓版 腾讯猎鱼达人手机版V2.3.0.0 官方安卓版
腾讯猎鱼达人手机版V2.3.0.0 官方安卓版 劲舞团官方正版手游v1.2.1官方版
劲舞团官方正版手游v1.2.1官方版 饥饿鲨鱼进化无限钻石版v7.8.0.0安卓版
饥饿鲨鱼进化无限钻石版v7.8.0.0安卓版 植物大战僵尸全明星1.0.91 安卓版
植物大战僵尸全明星1.0.91 安卓版 地下城突击者bt版1.6.3 官方版
地下城突击者bt版1.6.3 官方版 装甲联盟1.325.157 安卓版
装甲联盟1.325.157 安卓版 圣斗士星矢集结v4.2.1 安卓版
圣斗士星矢集结v4.2.1 安卓版 遮天3D手游1.0.9安卓版
遮天3D手游1.0.9安卓版 安卓植物大战僵尸2黑暗时代修改版V1.9.5 最新版
安卓植物大战僵尸2黑暗时代修改版V1.9.5 最新版 乱斗西游2v1.0.150安卓版
乱斗西游2v1.0.150安卓版 保卫萝卜3无限钻石最新版v2.0.0.1 安卓版
保卫萝卜3无限钻石最新版v2.0.0.1 安卓版 口袋英雄单机版1.2.0 安卓版
口袋英雄单机版1.2.0 安卓版 小小军团安卓版2.7.4 无限金币修改版
小小军团安卓版2.7.4 无限金币修改版 登山赛车2手游1.47.1 安卓版
登山赛车2手游1.47.1 安卓版 一起来飞车安卓版v2.9.14 最新版
一起来飞车安卓版v2.9.14 最新版 跑跑卡丁车手机版官方最新版v1.16.2 安卓版
跑跑卡丁车手机版官方最新版v1.16.2 安卓版 狂野飙车8极速凌云修改版(免数据包)v4.6.0j 金币无限版
狂野飙车8极速凌云修改版(免数据包)v4.6.0j 金币无限版 百乐千炮捕鱼2021最新版5.78 安卓版
百乐千炮捕鱼2021最新版5.78 安卓版 梦幻剑舞者变态版1.0.1.2安卓版
梦幻剑舞者变态版1.0.1.2安卓版 仙境传说ro复兴安卓版1.20.3最新版
仙境传说ro复兴安卓版1.20.3最新版 梦幻诛仙手游版1.3.6 官方安卓版
梦幻诛仙手游版1.3.6 官方安卓版 王者荣耀V3.72.1.1 安卓最新官方版
王者荣耀V3.72.1.1 安卓最新官方版 谁家小车强手机版v1.0.49 安卓版
谁家小车强手机版v1.0.49 安卓版 mac磁盘分区工具(Paragon Camptune X)V10.8.12官方最新版
mac磁盘分区工具(Paragon Camptune X)V10.8.12官方最新版 苹果操作系统MACOSX 10.9.4 Mavericks完全免费版
苹果操作系统MACOSX 10.9.4 Mavericks完全免费版 Rar解压利器mac版v1.4 官方免费版
Rar解压利器mac版v1.4 官方免费版 Mac安卓模拟器(ARC Welder)v1.0 官方最新版
Mac安卓模拟器(ARC Welder)v1.0 官方最新版 Charles for MacV3.9.3官方版
Charles for MacV3.9.3官方版 搜狗浏览器mac版v5.2 官方正式版
搜狗浏览器mac版v5.2 官方正式版 锐捷客户端mac版V1.33官方最新版
锐捷客户端mac版V1.33官方最新版 快牙mac版v1.3.2 官方正式版
快牙mac版v1.3.2 官方正式版 极点五笔Mac版7.13正式版
极点五笔Mac版7.13正式版 Apple Logic Pro xV10.3.2
Apple Logic Pro xV10.3.2 Adobe Premiere Pro CC 2017 mac版v11.0.0 中文版
Adobe Premiere Pro CC 2017 mac版v11.0.0 中文版 千千静听Mac版V9.1.1 官方最新版
千千静听Mac版V9.1.1 官方最新版 Mac网络直播软件(MacTV)v0.121 官方最新版
Mac网络直播软件(MacTV)v0.121 官方最新版 Adobe Fireworks CS6 Mac版CS6官方简体中文版
Adobe Fireworks CS6 Mac版CS6官方简体中文版 AutoCAD2015 mac中文版本v1.0 官方正式版
AutoCAD2015 mac中文版本v1.0 官方正式版 Adobe Photoshop cs6 mac版v13.0.3 官方中文版
Adobe Photoshop cs6 mac版v13.0.3 官方中文版 Mac矢量绘图软件(Sketch mac)v3.3.2 中文版
Mac矢量绘图软件(Sketch mac)v3.3.2 中文版 Adobe After Effects cs6 mac版v1.0中文版
Adobe After Effects cs6 mac版v1.0中文版 Adobe InDesign cs6 mac1.0 官方中文版
Adobe InDesign cs6 mac1.0 官方中文版![Mac版快播1.1.26 官方正式版[dmg]](https://p.e5n.com/up/2014-8/201484111558.jpg) Mac版快播1.1.26 官方正式版[dmg]
Mac版快播1.1.26 官方正式版[dmg] Mac读写NTFS(Paragon NTFS for Mac)12.1.62 官方正式版
Mac读写NTFS(Paragon NTFS for Mac)12.1.62 官方正式版 迅雷10 for macv3.4.1.4368 官方最新版
迅雷10 for macv3.4.1.4368 官方最新版 Mac下最强大的系统清理工具(CleanMyMac for mac)v3.1.1 正式版
Mac下最强大的系统清理工具(CleanMyMac for mac)v3.1.1 正式版 苹果BootCamp5.1.5640 官方最新版
苹果BootCamp5.1.5640 官方最新版 微信ipad版2020v7.0.12 官方版
微信ipad版2020v7.0.12 官方版 iphone手机qq2021v8.5.0 官方版
iphone手机qq2021v8.5.0 官方版 易信iOS版v7.3.13 iPhone版
易信iOS版v7.3.13 iPhone版 陌陌 iphoneV8.32.4 官方正式版
陌陌 iphoneV8.32.4 官方正式版 千牛 iphone版9.2.5 官方版
千牛 iphone版9.2.5 官方版 99严选最新版V1.3.6
99严选最新版V1.3.6 快牙iPhone版5.7.3 官方版
快牙iPhone版5.7.3 官方版 淘宝 for iPhonev9.5.15 官方最新版
淘宝 for iPhonev9.5.15 官方最新版 墨迹天气 for iphoneV7.5.3官方最新版IPA
墨迹天气 for iphoneV7.5.3官方最新版IPA 谷歌地图iphone(Google Maps)4.54 中文版
谷歌地图iphone(Google Maps)4.54 中文版![快播苹果版V3.3.35 官方版[ipa]](https://p.e5n.com/up/2011-12/20111215155620.gif) 快播苹果版V3.3.35 官方版[ipa]
快播苹果版V3.3.35 官方版[ipa] 吉吉影音播放器ios版1.0.1017 苹果ipad版
吉吉影音播放器ios版1.0.1017 苹果ipad版 影音先锋播放器ios版2.8.0 官方版
影音先锋播放器ios版2.8.0 官方版 斗鱼直播客户端ios版7.0.1 官方最新版
斗鱼直播客户端ios版7.0.1 官方最新版 酷狗音乐 for iPhonev10.9.0 官方最新版
酷狗音乐 for iPhonev10.9.0 官方最新版 How old do I look ios版1.02 官方版
How old do I look ios版1.02 官方版 美图秀秀iPhone版V8.6.62 最新正式版
美图秀秀iPhone版V8.6.62 最新正式版 水印队长苹果版v1.0.0
水印队长苹果版v1.0.0 天天p图ipad版5.7.4 官方版
天天p图ipad版5.7.4 官方版 快手ios版V9.6.30 官方版
快手ios版V9.6.30 官方版 背包地图ios版1.0 官方最新版
背包地图ios版1.0 官方最新版 手机安全助手苹果版v1.0 官方最新版
手机安全助手苹果版v1.0 官方最新版 UC浏览器V113.5.5.1555中文版
UC浏览器V113.5.5.1555中文版 360浏览器HD for iPadV4.1.3 正式版
360浏览器HD for iPadV4.1.3 正式版 iPhone手机QQ浏览器V8.9.1 官方版
iPhone手机QQ浏览器V8.9.1 官方版
最近在研究"一致性HASH算法"(Consistent Hashing),用于解决memcached集群中当服务器出现增减变动时对散列值的影响。后来 在JAVAEYE上的一篇文章中,找到了其中的 KetamaHash 算法的JAVA实现(一种基于虚拟结点的HASH算法),于是为了加深理解,对照 JAVA版本,用C#重写了一个。放到这里,如果大家感兴趣的话, 可以下载测试一下,如果发现写法有问题请及时告之我,以便我及时修正。
下面是对Ketama的介绍:
Ketama is an implementation of a consistent hashing algorithm, meaning you can add or remove servers from the memcached pool without causing a complete remap of all keys.
Here’s how it works:
* Take your list of servers (eg: 1.2.3.4:11211, 5.6.7.8:11211, 9.8.7.6:11211)
* Hash each server string to several (100-200) unsigned ints
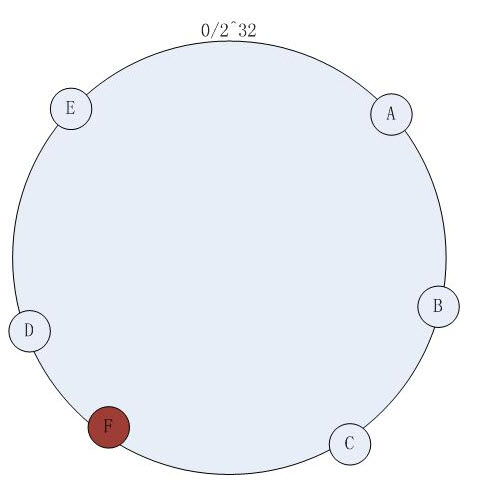
* Conceptually, these numbers are placed on a circle called the continuum. (imagine a clock face that goes from 0 to 2^32)
* Each number links to the server it was hashed from, so servers appear at several points on the continuum, by each of the numbers they hashed to.
* To map a key->server, hash your key to a single unsigned int, and find the next biggest number on the continuum. The server linked to that number is the correct server for that key.
* If you hash your key to a value near 2^32 and there are no points on the continuum greater than your hash, return the first server in the continuum.
If you then add or remove a server from the list, only a small proportion of keys end up mapping to different servers.
我的理解,这类方法其实有点像大学里的微积分的思想(通过连续函数的取值区间来计算图形面积)。通过把已知的实结点(memcached服务IP端口)列表结成一个圆,然后在两两实结点之间“放置”尽可能多的虚拟节点(上面文中的unsigned ints), 假设用户数据映射在虚拟节点上(用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上),这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。如下图:

下面是添加结点时:
如这篇文章所说(总结一致性哈希(Consistent Hashing) ):
Consistent Hashing最大限度地抑制了hash键的重新分布。另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上。因为使用一般的hash方法,服务器的映射地点的分布非常不均匀。使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。
了解了原理,下面看一下具体实现。
JAVA实现代码取自Spy Memcached client中的类,原文的作者也尽可能的对代码进行注释说明,所以让我剩了不少时间。
本文导航
- 第1页: 首页
- 第2页: 相应的.NET实现
- 第3页: .net版本下的测试结果
 喜欢
喜欢  顶
顶 难过
难过 囧
囧 围观
围观 无聊
无聊