
��Ҫ�������Դ������㷨��Ҫ��ʱ���㷨�ó�����Ӧ�õ�ʵ�ʿ����У�
���������������ڰٶ������˵�ͼƬ�����࣬Ҳ�ͼ����Űɣ������в�����ŮͼƬ�£��������������Ҳ�˵ͼƬ����ô��õģ������ĵõ�ͼƬ�Ժ������¡�
�����ĵ�һ�����������ЩͼƬû�к�������windows�£�û�к������ļ��Dz�����ȷ��ʶ��ģ�û��Ԥ������ʱ��Ҫѡ���ʽ���Ѿ����������Ƚ����������ÿ��ͼƬ���Ϻ��������ˡ�û�к�����ͼƬҲ���࣬����1000�Űɣ�һ��һ�ŵظĺ��鷳����������ѧ������ģ�����д�˸�����������http://www.cnblogs.com/ma6174/archive/2012/05/04/2482378.html���������������ˡ���������������һ�������⣺ͼƬ���ˣ���������ظ��ģ���ЩͼƬ��ȫһ����û�б�Ҫ�����ţ��Ҿ�������е��ظ�ͼƬ��ɾ����
������������һ��������⣺���ȣ��ļ������dz��࣬�ֹ������Dz���ʵ�ģ���˵����ƾ�������ۣ��ڼ�ǧ��ͼƬ�����ҵ���ȫ��ͬ���Ѷ�Ҳ�Ǻܴ�ġ��������ͼƬ���������ĵ����ڲ���Ԥ���������Ҫ��ȷ�����Ǻ����ѵġ�����Ҫ�ó���ʵ�֡���ô�ó�����ôʵ���أ�����ʲô�ж������ļ���ȫ��ͬ�أ����ȣ������ļ����ж��ǿ���ס�ģ���Ϊ�ļ������Ա�������ģ����ļ����ݲ��䡣��˵��ͬһ���ļ������棬Ҳ�����ܳ���������ȫ��ͬ���ļ���������ϵͳ�������ġ�����һ�ַ������Ǹ����ļ���С���жϣ��ⲻʧΪһ�ֺð취�����ǣ��ļ���С��ͬ��ͼƬ���ܲ�һ������˵ͼƬһ�㶼�Ƚ�С������3M�Ļ���û�У��ֲ���1M������ļ��������ļ��ر�࣬���ִ�С��ͬ�ĵ��ļ����������൱��ġ����Ե�ƾ�ļ���С���Ƚϲ����ס�����һ�ַ����Ƕ�ȡÿ��ͼƬ�����ݣ�Ȼ��Ƚ����ͼƬ�����ݺ�����ͼƬ�Ƿ���ȫ��ͬ�����������ͬ��ô������ͼƬ�϶�����ȫ��ͬ�ġ����ַ����������DZȽ������ģ�������������һ������ʱ��Ч�ʣ�����ÿ��ͼƬ�����ݶ�Ҫ������ͼƬ���бȽϣ������һ������ѭ������ȡ��Ч�ʵͣ��Ƚϵ�Ч�ʸ��ͣ����еĶ��Ƚ������Ƿdz���ʱ�ģ��ڴ淽�棬���Ԥ�Ȱ�����ͼƬ��ȡ���ڴ���Լӿ��ļ��ıȽ�Ч�ʣ�������ͨ��������ڴ���Դ���ޣ����ͼƬ�dz��࣬�ü���G�Ļ����������ڴ��Dz���ʵ�ġ�����������е��ļ���ȡ���ڴ棬��ôÿ�Ƚ�һ��֮ǰ��Ҫ�ȶ�ȡ�ļ����ݣ��Ƚϼ��ξ�Ҫ��ȡ���Σ���Ӳ�̶�ȡ�����DZȽ����ģ���������Ȼ�����ʡ���ô��û�и��õķ����أ���ڤ˼���룬�ʾ���֭������뵽��md5��md5��ʲô���㲻֪���𣿶������ˣ�ץ��ʱ��duckduckgo�ɣ�Ҳ������ʣ�md5���Ǽ��ܵ��𣿺����ǵ������й�ϵ���ʵúã�md5�������ⳤ�ȵ��ַ������м��ܺ��γ�һ��32���ַ����У��������ֺ���ĸ����д��Сд������Ϊ�ַ����κ�С�ı䶯���ᵼ��md5���иı䣬���md5���Կ���һ���ַ����ġ�ָ�ơ����ߡ���ϢժҪ������Ϊmd5�ַ����ܹ���3632��������������ͬ���ַ����õ�һ����ͬ��md5�����Ǻ�С�ģ�����Ϊ0��ͬ���ĵ��������ǿ��Եõ�ÿ���ļ���md5�������ļ���md5��ͬ�Ļ��ͻ����Ͽ��Կ϶������ļ�����ͬ�ģ���Ϊmd5��ͬ���ļ���ͬ�ĸ���̫С�ˣ��������Ժ��ԣ��������ǾͿ������������õ�ÿ���ļ���md5��ͨ���Ƚ�md5�Ƿ���ͬ���ǾͿ���ȷ������ͼƬ�Ƿ���ͬ�������Ǵ���ʵ�֣�python��
# -*- coding: cp936 -*-
import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5=[]
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1;
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
filemd5=getmd5(real_path)
if filemd5 in all_md5:
total_delete += 1
print 'ɾ��',file
else:
all_md5.append(filemd5)
end = now()
time_last = end - start
print '�ļ�������',total_file
print 'ɾ��������',total_delete
print '��ʱ��',time_last,'��'
if __name__=='__main__':
main()
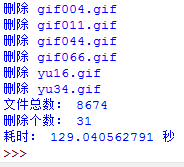
����ij���ԭ���ܼ��������ζ�ȡÿ���ļ�������md5�����md5��md5�б������ڣ��Ͱ����md5�ӵ�md5�б�����ȥ��������ڵĻ������Ǿ���Ϊ���md5��Ӧ���ļ��Ѿ����ֹ������ͼƬ���Ƕ���ģ�Ȼ�����ǾͿ������ͼƬɾ���ˡ������dz�������н�ͼ��

���ǿ��Կ�����������ļ���������8674���ļ�����31�����ظ��ģ��ҵ������ظ��ļ�����ʱ155.5�롣Ч�ʲ���ߣ��ܲ��ܽ����Ż��أ��ҷ�����һ�£��ҵij����������������ܱȽϺ�ʱ�䣬һ���Ǽ���ÿ���ļ���md5�����ռ�˴�ʱ�䣬���о������б��в���md5�Ƿ���ڣ�Ҳ�ȽϷ�ʱ��ġ��������������֣����ǿ��Խ�һ���Ż���
����������ǽ���������⣬�������ǿ��Զ��б��е�Ԫ������һ����Ȼ����ȥ���ң������б��DZ仯�ģ�ÿ�ζ�����Ļ�Ч�ʾͱȽϵ��ˡ�������������ֵ�����Ż����ֵ����������ص���һ��key��Ӧһ��ֵ���ǿ���md5��Ϊkey��key��Ӧ��ֵ�Ͳ���Ҫ�ˣ��ڱ仯��������ֵ�IJ���Ч�ʱ�����Ч�ʸߣ���Ϊ����������ģ����ֵ�������ģ�����������Ȼ���졣��������ֻҪ�ж�md5ֵ�Ƿ������е�key�оͿ����ˡ������ǸĽ���Ĵ��룺
# -*- coding: cp936 -*-
import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5={}
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1;
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
filemd5=getmd5(real_path)
if filemd5 in all_md5.keys():
total_delete += 1
print 'ɾ��',file
else:
all_md5[filemd5]=''
end = now()
time_last = end - start
print '�ļ�������',total_file
print 'ɾ��������',total_delete
print '��ʱ��',time_last,'��'
if __name__=='__main__':
main()
�ٿ������н�ͼ
��ʱ���Ͽ���ȷʵ��ԭ������һ�㣬���ǻ������롣���滹Ҫ�����Ż�������ʲô�����Ż��أ�md5������ij���ÿ���ļ���Ҫ����md5���dz���ʱ�䣬�Dz���ÿ���ļ�����Ҫ����md5�أ��ܲ�����취����md5�ļ�������أ����뵽��һ�ַ������������ʱ�����ᵽ������ͨ���Ƚ��ļ���С�ķ�ʽ���ж�ͼƬ�Ƿ���ȫ��ͬ���ٶȿ죬�������ַ����Dz�ȷ�ģ�md5��ȷ�ģ������ܲ��ܰ����߽��һ�£����ǿ϶��ġ����ǿ����϶�����������ļ���ȫ��ͬ����ô�������ļ��Ĵ�С��md5һ����ͬ����������ļ��Ĵ�С��ͬ����ô�������ļ��϶���ͬ�������Ļ�������ֻ��Ҫ�Ȳ鿴�ļ��Ĵ�С�Ƿ������size�ֵ��У���������ڣ��ͽ������뵽size�ֵ��У������С���ڵĻ�����˵������������ͼƬ��С��ͬ����ô����ֻҪ�����ļ���С��ͬ���ļ���md5�����md5��ͬ����ô�������ļ��϶���ȫһ�������ǿ���ɾ�������md5��ͬ�����ǰ����ӵ��б����棬�����ظ�����md5.�������ʵ�����£�
# -*- coding: cp936 -*-
import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5 = {}
all_size = {}
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
size = os.stat(real_path).st_size
name_and_md5=[real_path,'']
if size in all_size.keys():
new_md5 = getmd5(real_path)
if all_size[size][1]=='':
all_size[size][1]=getmd5(all_size[size][0])
if new_md5 in all_size[size]:
print 'ɾ��',file
total_delete += 1
else:
all_size[size].append(new_md5)
else:
all_size[size]=name_and_md5
end = now()
time_last = end - start
print '�ļ�������',total_file
print 'ɾ��������',total_delete
print '��ʱ��',time_last,'��'
if __name__=='__main__':
main()
ʱ��Ч�������أ�����ͼ��
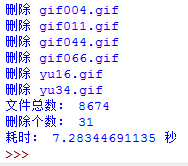
ֻ����7.28�룡��ǰ����Ч�������ʮ���������ʱ�仹���Խ���
�㷨�Ǹ�������Ķ��������������һ�»������벻�����ջ�����Ĵ��뻹���Խ�һ���Ż�������Ľ������㷨�ȣ�������ɶ�뷨���Ժ��ҽ���һ�¡�����C������ʵ�ֿ��ܻ���졣�Ǻǣ���ϲ��python�ļ�࣡
���������賿�����������죬�������컹�п��أ����磡˯��ȥ��............
��˯�С�������
 ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����



