
















Orange 是一个基于组件的数据挖掘和机器学习软件套装,它的功能即友好,又很强大,快速而又多功能的可视化编程前端,以便浏览数据分析和可视化,基绑定了Python以进行脚本开发。它包含了完整的一系列的组件以进行数据预处理,并提供了数据帐目,过渡,建模,模式评估和勘探的功能。其由C++ 和 Python开发,它的图形库是由跨平台的Qt框架开发。
数据是怎么导 入Orange里的:
具体操作是用python吗
你数据是存在哪儿的,如果是存在mysql里面的,那可以 使用orngMySQL和orngSQL模块,如下所示 t=orngMySQL.Connect('localhost','root','','test') data=t.query("SELECT * FROM busclass") tree=orngTree.TreeLearner(data) orngTree.printTxt(tree,nodeStr="%V (%1.0N)",leafStr="%V (%1.0N)")
Orange怎么用?
Orange是类似KNIME和Weka KnowledgeFlow的数据挖掘工具,它的图形环境称为Orange画布(OrangeCanvas),用户可以在画布上放置分析控件(widget),然后把控件连接起来即可组成挖掘流程。这里的控件和KNIME中的节点是类似的概念。每个控件执行特定的功能,但与KNIME中的节点不同,KNIME节点的输入输出分为两种类型(模型和数据),而Orange的控件间可以传递多种不同的信号,比如learners, classifiers, evaluation results, distance matrices, dendrograms等等。Orange的控件不象KNIME的节点分得那么细,也就是说要完成同样的分析挖掘任务,在Orange里使用的控件数量可以比KNIME中的节点数少一些。
Orange的好处是使用更简单一些,但缺点是控制能力要比KNIME弱。
除了界面友好易于使用的优点,Orange的强项在于提供了大量可视化方法,可以对数据和模型进行多种图形化展示,并能智能搜索合适的可视化形式,支持对数据的交互式探索。
Orange的弱项在于传统统计分析能力不强,不支持统计检验,报表能力也有限。Orange的底层核心也是采用C++编写,同时允许用户使用Python脚本语言来进行扩展开发。


支持Python的Orange数据挖掘软件实例:
Orange的特点是界面友好易于使用,提供大量可视化方法,提供Python编程接口,于是决定试用一下。
网上可以搜索到的Orange中文资料不多,这篇《利用orange进行关联规则挖掘》 给了一个通过Python调用Orange中的Apriori算法进行关联分析的例子,更详细的通过Python调用Orange的文档参考官网上的Beginning with Orange.图形界面的使用没看到文档,不过界面简单易懂,看看features里的screenshots也可猜个大概。参考Beginning with Orange中的Classification小节,以用Naive Bayesian Classifer处理Orange自带的示例数据集voting.tab为例,对代码做了少量修改:
#-*- encoding: utf-8 -*-
# 导入orange包
import orange
# 导入测试数据voting.tab
data = orange.ExampleTable("voting")
# 使用Naive Bayesian Classifer
classifier = orange.BayesLearner(data)
# 输出
all_data = len(data)
bingo = 0
for d in data:
# 分类器输出的类别
cc = classifier(d)
# 原文件中数据中的类别
oc = d.getclass()
if oc == cc:
print 'bingo!',
bingo += 1
else:
print 'oh,no!',
print "original", oc, "classified as", cc
# 输出Classification Accuracy
print "CA: %.4f" % (float(bingo)/all_data)
运行上面的代码,可得到如下输出:
bingo! original republican classified as republican
……
bingo! original republican classified as republican
bingo! original republican classified as republican
CA: 0.9034
分类准确率CA为0.9034.
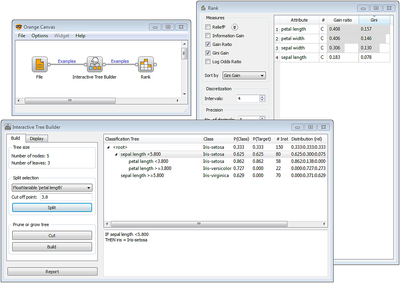
Python调用非常容易,只用了十几行代码,不过如果用图形界面,这个简单的分类只需要选择Data->File,Classify->Naive Bayes和Evaluate->Test Learners就行了,如下图所示,在File窗口中选择Data File为voting.tab,通过简单的拖拉将widget连起来即可,双击Test Learners可以看到CA为0.9011.
对比Python代码的输出和图形界面的结果,会发现两个结果不一致,原因是图形界面中使用的是5重交叉验证,而代码中使用的训练数据,如果选择”Test on train data”,两者就一致了。





 大小: 115.3M
大小: 115.3M

 Visual Foxpro 6.0 (VFP6.0)简体中文版
Visual Foxpro 6.0 (VFP6.0)简体中文版  MySQL图形管理工具(SQLyog MySQL)v12.0.9 中文特别版
MySQL图形管理工具(SQLyog MySQL)v12.0.9 中文特别版  Sqlite工具(SqliteStudio)v3.3.3 绿色中文版
Sqlite工具(SqliteStudio)v3.3.3 绿色中文版  MySQL图形管理工具(SQLyog)10.2 绿色中文版
MySQL图形管理工具(SQLyog)10.2 绿色中文版  sql server 2000数据库管理简体中文版
sql server 2000数据库管理简体中文版  mysql图形化界面软件(navicat 8 for mysql)8.2.12 中文版
mysql图形化界面软件(navicat 8 for mysql)8.2.12 中文版  高效开源数据库(mongodb)V3.4.10 官方正式版
高效开源数据库(mongodb)V3.4.10 官方正式版  MySQL-Front(Mysql管理工具)V5.3.2.42 中文官方安装版
MySQL-Front(Mysql管理工具)V5.3.2.42 中文官方安装版  数据库比较同步工具(SQL Compare)10.4.8.87 完整版
数据库比较同步工具(SQL Compare)10.4.8.87 完整版  aqua data studio 18.564位汉化版
aqua data studio 18.564位汉化版  极佳数据库恢复工具v3.1 绿色免费版
极佳数据库恢复工具v3.1 绿色免费版  MySQL集群(MySQL Cluster)7.6.9 官方最新版
MySQL集群(MySQL Cluster)7.6.9 官方最新版  CouchDBV1.0.1 免费版
CouchDBV1.0.1 免费版