












pdf提取表格内容源码,一个pdf提取表格内容的源码,由Python语言编写,参考文档为教育部阅读指导目录,用户可以通过源码原理来制作能提取任意表格内容的源码,下面给出这款pdf提取表格内容的源码资源,有需要的朋友们可以参考学习。
源码程序由论坛用户制作分享。

pdf提取表格内容源码功能
一个从pdf文档中提取出表格数据,并另存为excel文件的python程序
pdf提取表格内容源码说明
教育部基础教育课程教材发展中心首次向全国中小学生发布阅读指导目录
http://www.moe.gov.cn/jyb_xwfb/gzdt_gzdt/s5987/202004/t20200422_445605.html
最下面的附件
pdf中按小学、初中、高中推荐了三套生阅读指导目录。
我们根据页码,来分别存为3个EXCEL文件。
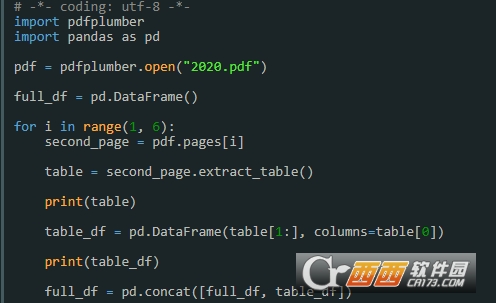
源码一览
# -*- coding: utf-8 -*-
import pdfplumber
import pandas as pd
pdf = pdfplumber.open("2020.pdf")
full_df = pd.DataFrame()
for i in range(1, 6):
second_page = pdf.pages[i]
table = second_page.extract_table()
print(table)
table_df = pd.DataFrame(table[1:], columns=table[0])
print(table_df)
full_df = pd.concat([full_df, table_df])
full_df.to_excel('小学段.xlsx')
full_df = pd.DataFrame()
for i in range(6, 11):
second_page = pdf.pages[i]
table = second_page.extract_table()
print(table)
table_df = pd.DataFrame(table[1:], columns=table[0])
print(table_df)
full_df = pd.concat([full_df, table_df])
full_df.to_excel('初中段.xlsx')
full_df = pd.DataFrame()
for i in range(11, 15):
second_page = pdf.pages[i]
table = second_page.extract_table()
print(table)
table_df = pd.DataFrame(table[1:], columns=table[0])
print(table_df)
full_df = pd.concat([full_df, table_df])
full_df.to_excel('高中段.xlsx')

 大小: 109KB
大小: 109KB
 大小: 131M
大小: 131M
 大小: 110.6M
大小: 110.6M PHP和MySQL Web开发第4版源代码
PHP和MySQL Web开发第4版源代码  SSH框架整合小案例
SSH框架整合小案例  51单片机150个例程
51单片机150个例程  PHP操作excel类(PHPExcel)1.7.7
PHP操作excel类(PHPExcel)1.7.7  逐梦旅程:Windows游戏编程之从零开始 配套源代码
逐梦旅程:Windows游戏编程之从零开始 配套源代码  HTML 5开发精要与实例详解 配套源码
HTML 5开发精要与实例详解 配套源码  HTML-CSS-JavaScript标准教程实例版
HTML-CSS-JavaScript标准教程实例版  c语言经典编程900例
c语言经典编程900例  C# 教务管理系统源码
C# 教务管理系统源码  C++Builder学习大全中文版
C++Builder学习大全中文版