

















批量删除同名电子书(保留指定格式)是一款Python批量删除同名电子书籍工具助手,小书库清理走起,陆陆续续存了上百G的电子书,很多电子书同一本却有4种格式,epub,mobi,azw3, pdf,多浪费硬盘啊,寻遍全网,没有现成的软件,只能自己动手了。把其它格式的全删除了,留下epub格式的,慢慢欣赏就足够。
软件灵感:
昨晚和朋友聊微信,突然想起盘里的200多G电子书,有很多格式相同的,太占容量了,5万多本,占了快200多G,手动删除了一些不感兴趣的书籍。和朋友讨论如果写代码来删除一些同名但格式不同的电子书,处理流程应该怎么样。后来朋友突然说,其实用数据库也可以弄,而且很快:
第一步:用bat批处理遍历子目录的文件路径,我测试发现,5万多本的电子书,生成路径文本不用3秒就完成了,4M大小的文本。
第二步:导到数据库,分割出文件名,不带后缀名那种 ,排序,加上编号,然后拼接上绝对路径,再删除指定编号的(删除是为了保留同名的某一本电子书),剩下的就是同名且格式不同的电子书路径了。
第三步:在数据库上,给每行路径前加del /F /S /Q 命令,导出为文本,改后缀为bat,运行,即可把所有同名的电子书删除。
然后我就想了一下,还写啥程序,这用数据库,一下就能完成的事,写程序还要花一天时间,太傻了。。。然后因为不懂数据库,昨晚是用excel对5万多行的电子书进行分列,拼接等等处理,不熟悉,一边百度一边弄的。。。。还是忙了2小时,不懂数据库真惨。。。
今天一早起来,觉得还是不爽,我的电子书是处理完了,广大的吾友小书库满了怎么办,不懂程序的吾友,清理又不方便,所以还是嗑嗑碰碰,绞尽脑汁花了一天,写到现在发贴才写完python小工具《批量删除同名电子书 仅保留一本指定的格式》
使用说明:
第一步:双击运行《python小工具-批量删除同名电子保留指定格式》,默认是按epub>mobi>azw3>pdf>doc>chm>html>txt 顺序来保留电子书,简单说,如果你电脑里不同的文件夹里同时存在着多种格式的同一个名字的电子书,且其中有一本格式是epub,那么程序会保留epub格式的,如果没有epub,只有其它格式,程序会依上面的顺序,依次判断,最后,如果你的电子书格式在上面都没有,例如是ppt格式的,程序会自动保留一本,其它的一律删除。之所以优先保留epub,是因为其压缩率相对mobi高点,体积小点,两者排版差不多,以上关于epub和mobi的压缩率大小是我百度的。
第二步:回车后,会弹出窗口,你选择电子书所在的目录就行,会遍历子目录,列举出所有的电子书路径,千万不要选其它什么电脑软件或者非电子书的目录,免得把你电脑软件的一些文件误删除。
第三步:选完电子书目录后,静心等待就行,稍等片刻,会输出正在删除xxx路径电子书的字样,当有些电子书文件是只读属性, 会自动调用cmd命令强制删除。
第四步:当删除完毕后,会自动打开电子书所在的目录,到这一步,已经是完成整理了哦,看看你的硬盘省了多少内存(貌似是电子书是删除到回收站了,测试时没有留意,建议执行完毕后,清理一次回收站,再看看硬盘省下多少容量)。
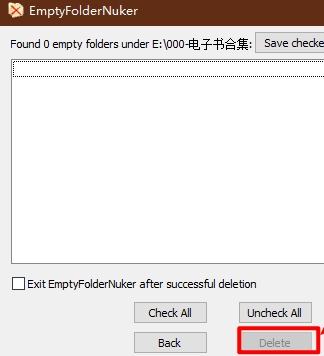
第五步:用下面我提供的 批量删除空文件夹软件,批量删除空的电子书目录。完美,哈哈。
注意事项:打个比方,如果你想优先保留azw3格式的电子书,不要其它格式的,那就修改源码中的
[("azw3", "AZW3"),("epub", "EPUB"), ("mobi", "MOBI"),("pdf", "PDF"), ("doc", "DOC"),("chm", "CHM"), ("html", "HTML"),("txt",
列表里的元组顺序。有编程底子的应该懂,这是列表里嵌入了元组。如果不懂编程的,修改时,要特别注意逗号大小写这些。
送到嘴上吧:打包了多种优先顺序不一样的exe,自行挑选使用那个
温馨提示:
请先复制一些相同名字但不同格式的电子书,分别扔到几个子目录文件夹里,用我的软件自行测试几次,观察使用后的结果是否和你预期的结果一致,再对自己的电子书库大批量使用。免得误删了你的电子书了,岂不找我拼命。
批量删除完同名电子书后,可能会有一些目录是空的,此是就用它来批量清理空目录
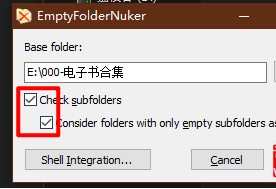
批量删除空文件夹的使用教程:
记得勾上下面的两个勾,否则不会删除空的子目录。
如果你想用数据库或excel来批量删除,可以下载下面这个批处理,提取绝对路径:批处理 遍历所有目录及子目录的文件路径
软件源码:
from tkinter.filedialog import * #这个主要作用是os模块 删除文件,和运行时弹出,让你们选择要删除书籍的目录。
from operator import itemgetter #这个模块好像可以根据2个条件来排序,下面用来根据 书名和后缀名 排序.
from os import startfile
#下面可能有些功能或变量是多少余的,算法不精,时间来凑,只能用比较笨的方法来实现。
# 整体思路:
# 和上面的excel处理差不多,都是先列举出电子书路径,然后根据相同的书名对路径排序,再剔除只有一本的书的路径,剩下的就是重复的书本路径了,然后再根据算法判断,优先剔除epub格#式的,其次是mobi,再到azw3,再到pdf,再到。。。。。。,如果指定的格式都没有,就从重复的路径列表中,去除第一个路径,剩下的电子书路径,都是重复的。最后,大胆的调用删除命#令,全部删删删删删删,如果删除出错,就调用cmd命令强制删除。
Files_Names={
"sort_list":[], #后面,这个元素列表,会存储以下信息 [绝对路径,电子书名,后缀名,同一本书的数量序号,是否重复]
"ml_name":""
}
def list_name(ml_name):
file_names = os.listdir(ml_name) # 根据选择的目录列出里面的文件及目录 返回值为列表
if file_names != "": # 只要返回的文件路径和目录路径不为空,防止你犯二,选择了一个没有文件的空目录
for i in range(0, len(file_names)): # 列表转换为循环数。
path = os.path.join(ml_name, file_names[i]) #电子书绝对路径 例如:E://电子书/1文件夹/家书.epub
if os.path.isfile(path): # 如果为真,则是文件
# 实际测试,发现有一些电子书,没有后缀名,故加上判断,没有.的大概率是没有后缀名的书籍,此类的就放弃,不整理。之所以判断.号是否存在于path[-6:]而不是判断是否存在整个绝对路径path中,是因为发现有些文件夹名带有.号,而此时存在这个文件夹里的电子书恰巧是没有后缀名的,这种情况就会造成误判认为其有后缀名。所以我才判断.号是否存在于path[-6:],而不用整个路径判断
if "." in path[-6:]:
hj=path.split(".")[-1] #分割出电子书后缀名 例如epub
name_nohj=path.split("/")[-1].replace("." + hj, "") #分割,替换去除后缀名,只剩下电子书名 例如:家书
Files_Names["sort_list"].append([path, name_nohj, hj]) #[绝对路径,电子书名,后缀名]
else: # 如果不是文件,那应该是目录,就加上/,再调用自身方法,进行递归列出下一层的文件,听说很多人在递归这里搞不明白。。。
try:
list_name(path + "/")
except:
print("访问目录出错,可能不是一个目录,或者是奇奇怪怪的文件名")
if __name__ == '__main__':
#format_hj变量用于 指定电子书优先留下的格式,在前面的格式元组是要优先留下的,因为epub相对mobi压缩率高,排版差不多,所以优先留下epub的,其次是mobi,再到azw3 .....最后到txt,如果你的电子书,都不属于下面的格式,那就不管格式了,自动留下第一本,其它重复的书就删了。
#如果你们要优先留下azw3格式的,只需要调一下 下面的元组顺序就行,把("azw3", "AZW3")放到第一。
format_hj = [ ("pdf", "PDF"), ("azw3", "AZW3"), ("mobi", "MOBI"), ("epub", "EPUB"),("doc", "DOC"),("chm", "CHM"), ("html", "HTML"),("txt", "TXT")]
Files_Names["ml_name"]=askdirectory() #选择电子书所在的目录并存到变量里,后面重命名完成后,调用这个变量,显示文件夹出来
if Files_Names["ml_name"]!="": #此判断为了防止你不选择文件夹,直接点了取消,此时返回空,就不执行遍历电子书功能。
Files_Names["ml_name"] += "/"
list_name(Files_Names["ml_name"]) # 把选择的目录传入到list_name方法中,进行递归遍历照片文件路径
aa=sorted(Files_Names["sort_list"], key=itemgetter(1,2)) #根据 书名和后缀名 排序,出来的效果就是 即使不同文件夹里,但名字相同的电子书,都会排在一起,方便后期用挑选需要的格式,和删除
# 例如:
# ['E:/电子书合集/20200101/豆瓣高分电子书合集/酒神.azw3', '酒神', 'azw3']
# ['E:/电子书合集/20200101/酒神.epub', '酒神', 'epub']
# ['E:/电子书合集/电子书/小说/酒神.mobi', '酒神', 'mobi']
# 循环判断,给电子书,加上数字序号,当遇到重复的书本就加1,遇到不同的书本,就恢复序号为1
for index,i in enumerate(aa):
num=1
if index!=0:
if (i[1] == q_i[1]):
num=q_i[3]+1 #数字序号增加
q_i = i
i.append(num)
#根据上面的数字序号,循环判断,是否重复,重复的加上”重“字,不重复即只有一本的,加上”不“字
for index,i in enumerate(aa):
repeat = "不"
if index!=0:
if (i[3] == q_i[3]+1):
q_i.pop()
q_i.append("重")
repeat="重"
q_i = i
i.append(repeat)
#把在电子书列表中,有 不 字的列表 直接 用倒序删除掉。 不能用顺序,这是一个坑
for i in range(len(aa) - 1, -1, -1):
if "不" in aa[i][4]:
del aa[i]
#下面再通过把同一本书不同格式,合并到同一个列表中。再塞到一个大列表里。
bbb=[] #瞎鸡乱定的变量名,当时心态已经崩了 小列表
ccc=[] #瞎鸡乱定的变量名,当时心态已经崩了 大列表
for index, i in enumerate(aa):
if index!=0:
if (i[3] == q_i[3]+1): #这里通过判断前一个和后一个的数量序号是否相等,判断是否同一本书
bbb.append(i) #是同一本书,就塞到小列表中
else:
ccc.append(bbb) #表示不是同一本书,就把当前的塞到大列表,结束,开始新的一轮加塞
bbb = [] #清空小列表
bbb.append(i) #往小列表加进新的一本书
else:
bbb.append(i) #第一本书,就塞到小列表中
q_i = i
ccc.append(bbb) #最后一本 塞进大列表
if len(ccc[0])!=0:
for i in ccc: #根据算法,删除需要的格式,留下不需要的格式电子书,后面就根据这些不需要的电子书绝对路径,循环删除。
for hj in format_hj: #这是要保留的格式
BOOL = False
for index,o in enumerate(i): #这里的i表示同一本书,但不同格式的列表,o表示具体的一本书的路径信息列表
if hj[0] in o[2] or hj[1] in o[2]:
i.pop(index)
BOOL=True
break
if BOOL:
break
if BOOL==False: #如果多本书名相同的电子书格式都不符合 format_hj指定的格式,就按顺序移除第一本,即保留第一本。
i.pop(0)
for i in ccc:
for o in i:
try:
os.remove(o[0])
print("删除:%s"%o[0])
except:
print("删除不了,将调用cmd命令删除!"+o[0])
o[0]=o[0].replace("/","\\") #不替换一下反斜杠,命令不生效
cmdd="del /F /S /Q "+o[0]
os.system(cmdd)
else:
print("竟然没有重名的书籍!恭喜!恭喜!恭喜!恭喜!恭喜!恭喜!")
startfile(Files_Names["ml_name"]) # 完成后自动打开 压缩图片所在的文件夹



 大小: 28.4M
大小: 28.4M
 大小: 5.3M
大小: 5.3M
 PDF文件转换成Word(Solid Converter PDF)10.0.9341.3476 中文特别版
PDF文件转换成Word(Solid Converter PDF)10.0.9341.3476 中文特别版  Restorator 2009V1807Bulid绿色中文免费版
Restorator 2009V1807Bulid绿色中文免费版  汉王PDF转Wordv8.1简体中文版
汉王PDF转Wordv8.1简体中文版  得力PDF转WORDv1.8.6.6 官方免费版
得力PDF转WORDv1.8.6.6 官方免费版  福昕PDF转Word转换器4.0.0.1211官方免费版
福昕PDF转Word转换器4.0.0.1211官方免费版  PDF修改器2.5.2.0 绿色免费版
PDF修改器2.5.2.0 绿色免费版  Flash转换工具Magic Swf2Avi2008 汉化特别版
Flash转换工具Magic Swf2Avi2008 汉化特别版  Excel文件修复工具(GetData Repair My Excel)v1.1.0.71 英文破解版
Excel文件修复工具(GetData Repair My Excel)v1.1.0.71 英文破解版  DocTranslate(翻译Doc和Ppt文档的语言)V1.1.0.2英文绿色版
DocTranslate(翻译Doc和Ppt文档的语言)V1.1.0.2英文绿色版  扬帆绿色软件制作工具那片叶子最终版
扬帆绿色软件制作工具那片叶子最终版  Cogniview PDF2XL Enterprise(把pdf转换excel工具)v4.6.0.179英文绿色特别版
Cogniview PDF2XL Enterprise(把pdf转换excel工具)v4.6.0.179英文绿色特别版  Abdio PDF Converter Pro(转换文件格式到PDF)V6.1英文安装版
Abdio PDF Converter Pro(转换文件格式到PDF)V6.1英文安装版  用友U8科目错误修正工具V1.0绿色版
用友U8科目错误修正工具V1.0绿色版  CFA FileList(快速的解出文件列表)V2.01英文安装版
CFA FileList(快速的解出文件列表)V2.01英文安装版  AJC Grep(文件搜索替换、数据提取)V1.3.4绿色英文特别版
AJC Grep(文件搜索替换、数据提取)V1.3.4绿色英文特别版  RecycleBinExV1.0.5.530 汉化绿色版
RecycleBinExV1.0.5.530 汉化绿色版  AJC Diffv1.91英文绿色特别版
AJC Diffv1.91英文绿色特别版  MetatOGGer(标签、重命名和安排Ogg和MP3文件)4.1 英文安装版
MetatOGGer(标签、重命名和安排Ogg和MP3文件)4.1 英文安装版