


















四川省教育考试院官网最新动态获取工具,由论坛大佬原创制作的一个能及时获取四川省教育考试院官网最新动态信息的获取程序,由Python语言编写。对于需要不断刷新想要第一时间获取最新信息的朋友们考生们可以下载这款EXE程序,一旦有更新就会立即通知,无需苦苦等待刷新。

四川省教育考试院官网最新动态获取工具使用
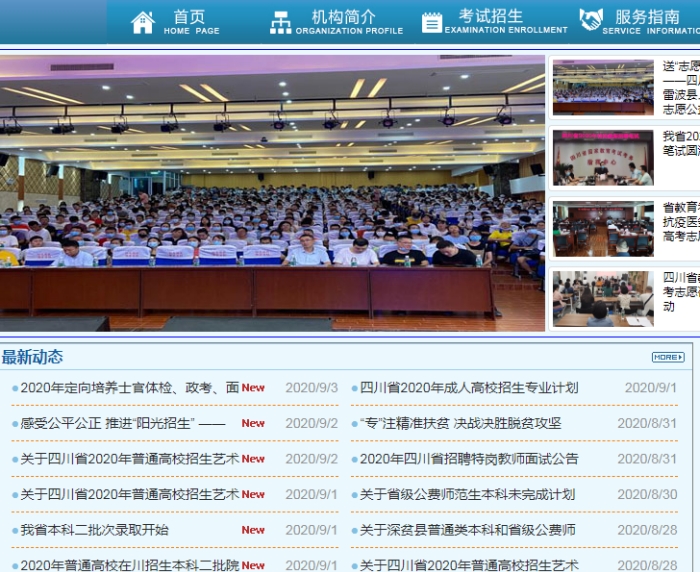
首先.访问官网www.sceea.cn
1.右击左边的列表,选择‘检查’
2.右击A标签
3.选择复制(copy)
4.复制Xpath路径,然后得到不同的属性值
四川省教育考试院官网最新动态获取工具代码
import requests
import time
from lxml import etree
import webbrowser
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
eduurl ='http://www.sceea.cn' # 四川教育考试院官网
alll = [] # 定义一个空列表,存放已访问过的标题
while True: # 死循环
HTMl = requests.get(eduurl, headers=headers).text
HTMl = etree.HTML(HTMl)
title = HTMl.xpath('//*[@id="news-left"]/li/a/@title') # 用Xpath获取文章标题
titletime = HTMl.xpath('//*[@id="news-left"]/li/span/span[2]/text()') # 用Xpath获取发布时间
urls = HTMl.xpath('//*[@id="news-left"]/li/a/@href') # 用Xpath获取文章连接
keyword = ['专科', '对口招生', '旅游', '高职'] # 建立一个关键字列表
for tit in title: # 在所有得到的标题里面遍历
for key in keyword: # 在所有关键字里面遍历
if key in tit: # 判断关键字出现在标题中
if tit in alll: # 判断标题在已访问过的标题列表里面
pass # 在里面就不作为
else: #
local = title.index(tit) # 获取标题在标题列表中的位置,用于得到发布时间
print(titletime[local] + ' ' + title[local] + '\n') # 打印出发布时间和文章标题
url = 'http://www.sceea.cn' + urls[local] # URL的拼接
webbrowser.open(url) # 打开浏览器,访问文章
alll.append(tit) # 将已访问的标题添加到列表中,防止重复访问
time.sleep(600) # 设置延迟10分钟,相当于10分钟刷新一次吧
相关说明
爬虫程序大部分功能通用,如果将代码中的官网以及相关设置进行替换,则可以获取其它教育网站的查询程序,源代码也在安装包内,可以下载学习

 大小: 67.8M
大小: 67.8M
 大小: 445KB
大小: 445KB
 12306订票助手扩展V10.4.0.0 免费版
12306订票助手扩展V10.4.0.0 免费版  Flash Player Square win7专版V11.2 官方安装版
Flash Player Square win7专版V11.2 官方安装版  小米5抢购神器2016电脑版
小米5抢购神器2016电脑版  熊猫tv弹幕助手V2.2.5.1192 官方绿色版
熊猫tv弹幕助手V2.2.5.1192 官方绿色版  百度关键词助手V4.0 绿色中文免费版
百度关键词助手V4.0 绿色中文免费版  CYY网页提取助手3.0 绿色版
CYY网页提取助手3.0 绿色版  免费流量监控V3.0.2009.1022 官方安装版
免费流量监控V3.0.2009.1022 官方安装版  Google Desktop(桌面搜索工具)V5.9.911.3589中文官方安装版
Google Desktop(桌面搜索工具)V5.9.911.3589中文官方安装版  猎豹浏览器强制雅黑字体插件0.1.0
猎豹浏览器强制雅黑字体插件0.1.0  CSS Compressor(CSS压缩器)V1.0 绿色中文免费版
CSS Compressor(CSS压缩器)V1.0 绿色中文免费版  网络类型判断器V1.0绿色中文免费版
网络类型判断器V1.0绿色中文免费版  LanLights(监视网络流量)V1.1.15绿色英文特别版
LanLights(监视网络流量)V1.1.15绿色英文特别版  敏感词过滤工具V1.0绿色中文免费版
敏感词过滤工具V1.0绿色中文免费版  HaisanIDS(新增ICMP包的数据分析和特征字符串监控等)V1.1绿色中文免费版
HaisanIDS(新增ICMP包的数据分析和特征字符串监控等)V1.1绿色中文免费版  微波炉V0.91 绿色中文免费版
微波炉V0.91 绿色中文免费版  石青支付宝推广大师V1.2.1.10免安装版
石青支付宝推广大师V1.2.1.10免安装版  Upiup随心动V1.0绿色中文免费版
Upiup随心动V1.0绿色中文免费版