
д��ƪ���°����Լ����õ�����������Ҳ�����Լ���ѧϰ�ʼǰɣ���������� ����������з����IJ���ȷ�ĵط�����ӭָ�� ��
һ. �ۼ�����B������
1.�ۼ�������B���ṹ������֯�ģ�����B���ֵ�ÿһҳ��Ϊһ�������ڵ㡣B���Ķ��˽ڵ��Ϊ���ڵ㡣
�����еĵͲ�ڵ��ΪҶ�ڵ㡣���ڵ���Ҷ�ڵ�֮����κ���������ͳ��Ϊ�м伶���ھۼ������У�Ҷ�ڵ����������������ҳ��
���ڵ���м伶�ڵ�������������е�����ҳ��ÿ�������а���һ����ֵ��һ��ָ�룬��ָ��ָ�� B ���ϵ�ijһ�м伶ҳ��Ҷ�������е�ij��������.ÿ�������е�ҳ����������˫�������б��С�
2.����ʹ�õ�ÿһ��������index_id = 1 ��Ĭ������¾ۼ�����������������ʹ�÷�������ʱ��ÿ����������һ���������ض�����������ݵ�B���ṹ��������ô����IJ�֪���Բ��ԣ�
3.SQL Server д������ݣ��������ڵ�ҳ���н����ۼ�������ֵ��������
4.SQL Server ���������в��Ҹ÷�Χ����ʼ��ֵ��Ȼ������ǰ�����������ҳ�н���ɨ�衣Ϊ�˲�������ҳ������ҳ��SQL Server ���������ĸ��ڵ�������ߵ�ָ�����ɨ�衣
�ۼ�����B��ͼ ��

�� .�Ż� Transact-SQL ��侭��ʹ�õ����
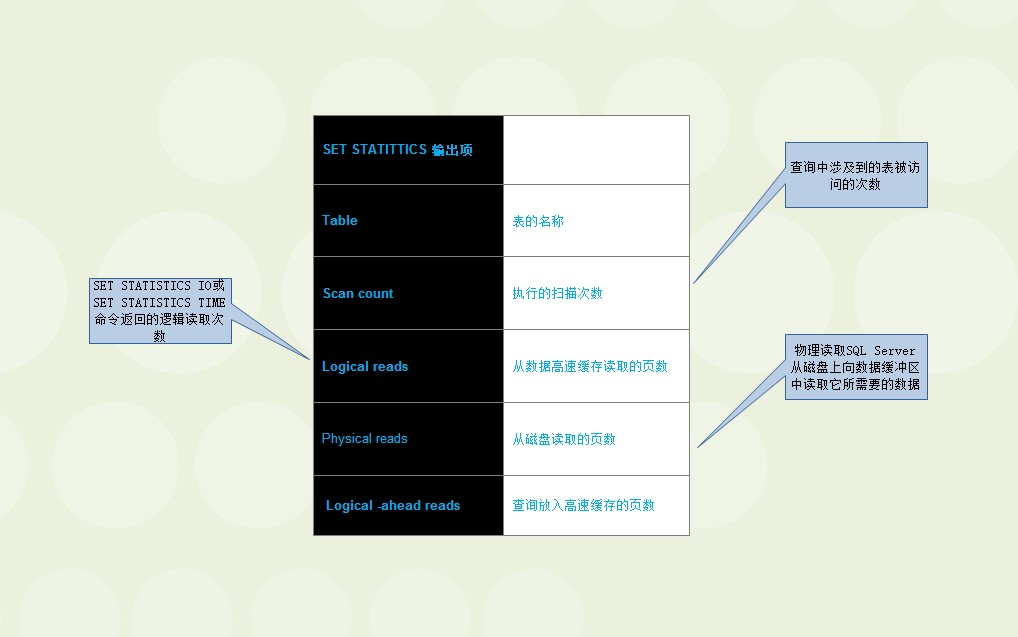
1.SET STATISTICS IO {ON| OFF} /*Transact-SQL ������ɵĴ��̻������Ϣ*/
2.SET SHOWPLAN_ALL ON {ON| OFF} /*�����й����ִ���������ϸ��Ϣ��������������Դ������*/
3.SET STATISTICS TIME {ON| OFF} /*��ʾ�����������ִ�и��������ĺ�����*/
4.ʹ��T-SQL��䴴�����������
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX index_name
ON table_name (column_name)
[WITH FILLFACTOR=x]
UNIQUE��ʾΨһ��������ѡCLUSTERED��NONCLUSTERED��ʾ�ۼ��������ǷǾۼ������� ��ѡ FILLFACTOR��ʾ������ӣ�ָ��һ��0��100֮���ֵ����ֵָʾ����ҳ�����Ŀռ���ռ�İٷֱ�
SET STATISTICS IO �����Ϣ��ͼ
�� �������ݲ���������ѧ��������֪ʶ
--������
CREATE TABLE employee
(
emp_username varchar (20),
emp_register DATETIME
)
--�����������
DECLARE @startid INT
DECLARE @endid INT
SELECT @startid= 1,@endid = 100
WHILE @startid <=@endid
BEGIN
INSERT INTO employee (
emp_username,
emp_register
) VALUES (
/* emp_username - varchar (20) */ '��'+CAST(@startid AS NVARCHAR(20)),
/* emp_register - DATETIME */ GETDATE() )
SELECT @startid =@startid +1;
END
-- ��ѯemployee��ִ�мƻ� �� io ��Ϣ
SET STATISTICS IO ON
SELECT * FROM employee WHERE emp_username = '��'

�鿴��Ϣ����� IO ��Ϣ
��'employee'��(1)1ɨ�����1��(2)����ȡ1 �Σ�(3)������ȡ0 �Σ�(4)Ԥ��0 �Σ�lob ����ȡ0 �Σ�lob ������ȡ0 �Σ�lob Ԥ��0 �Ρ�
�������Ϣ�������ͼƬ������Ƕ�Ӧ��
1. ִ�е�ɨ����� ��
2. �Ӵ��̶�ȡ��ҳ����
3. Ϊ���в�ѯ�����뻺���ҳ����
4. Ԥ��
T_SQL transaction ����кܶ��ֵ�д�������Ǿ���������������ŵ��Ǹ���(logical reads) ����ȡ���жϡ�
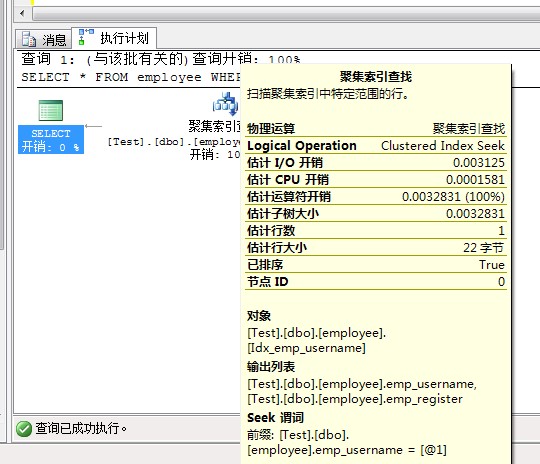
���Ӿۼ����� ��ѯ����ȡ�Ƿ�����
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
--Ȼ����ִ�в�ѯ
SET STATISTICS IO ON
SELECT * FROM employee WHERE emp_username = '��'
�鿴��Ϣ����� IO ��Ϣ
��'employee'��ɨ�����1������ȡ2 �Σ�������ȡ0 �Σ�Ԥ��0 �Σ�lob ����ȡ0 �Σ�lob ������ȡ0 �Σ�lob Ԥ��0 �Ρ�
Q �������ȡ��2��Ϊʲô�� ��
A.�ѵ���ѯ�ȱ�ɨ�軹Ҫ�������ǶԵģ�������С��ʱ�ۼ��������������ֲ�������
Q Ϊʲô��2������ȡ
A ���ڲ�ѯ��ʱ����ۼ�����ͼ���Ȳ�ѯ����ҳ �����ҵ���Ӧ�ļ�ֵ��ɨ������ҳ������а���������ֱ��������ҳ�Ϳ�����ȡ����Ҫ�����ݡ�
����˵��С��������ʱ��ۼ��������ֲ���Ч�����������Ǽ���������ݲ��� ��
���������ݵ�1000
��ɨ��
��Ϣ��
��'employee'��ɨ�����1������ȡ36 �Σ�������ȡ0 �Σ�Ԥ��0 �Σ�lob ����ȡ0 �Σ�lob ������ȡ0 �Σ�lob Ԥ��0 �Ρ�
�ۼ�����ɨ��
��Ϣ��
��'employee'��ɨ�����1������ȡ2 �Σ�������ȡ0 �Σ�Ԥ��0 �Σ�lob ����ȡ0 �Σ�lob ������ȡ0 �Σ�lob Ԥ��0 �Ρ�
���ʱ��ۼ����������ƾ�����ʾ������ O(∩_∩)O
������������transaction sql ��� ����������Ͽ�����һЩ��˵ In like left ��ʹ������ �����Ƕ����������¿�����˵�ĶԲ��� ��
ɾ��employee��������
DROP INDEX employee.Idx_emp_username
�� 'employee'��ɨ����� 1������ȡ 371 �Σ�������ȡ 0 �Σ�Ԥ�� 0 �Σ�lob ����ȡ 0 �Σ�lob ������ȡ 0 �Σ�lob Ԥ�� 0 �Ρ�
��IO��Ϣ
SET STATISTICS IO ON
SELECT * FROM employee WHERE employee.emp_username in ('��10000')
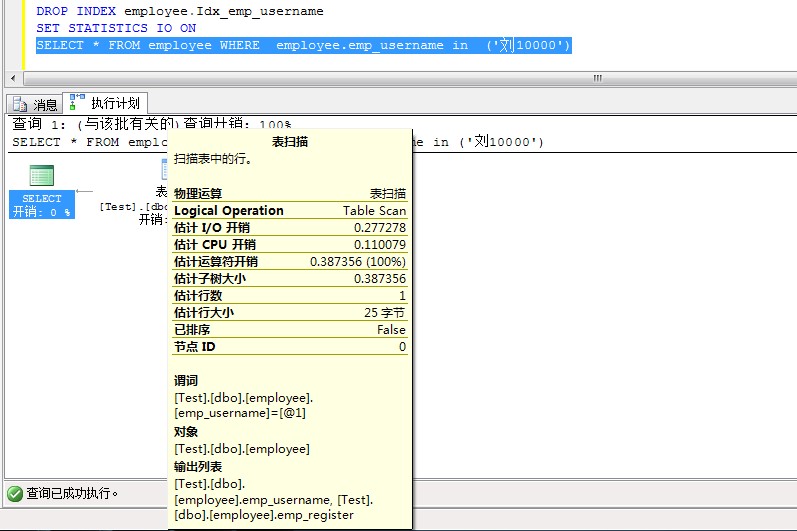
��Ϣ��
--����Idx_emp_username�ۼ�����
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
SELECT * FROM employee WHERE employee.emp_username in ('��10000');
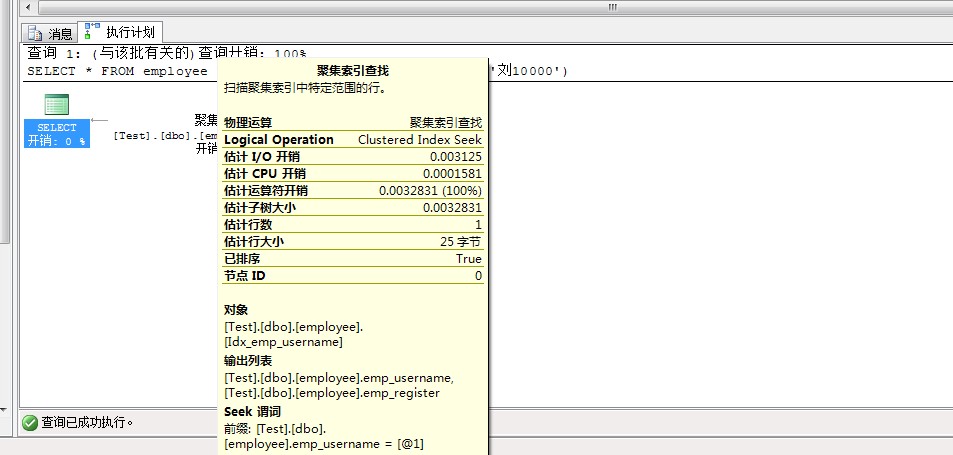
��Ϣ:
�� 'employee'��ɨ����� 1������ȡ 3 �Σ�������ȡ 0 �Σ�Ԥ�� 0 �Σ�lob ����ȡ 0 �Σ�lob ������ȡ 0 �Σ�lob Ԥ�� 0 �Ρ�
ʹ������������ȡ3�Σ�û��ʹ��������371�Σ�IN �ܺõ�ʹ����������
���������������� LIKE �Ƿ�ܺõ�ʹ������
ɾ������
DROP INDEX employee.Idx_emp_username
��IO ��Ϣ
SET STATISTICS IO ON
ִ�в�ѯ
SELECT * FROM employee WHERE employee.emp_username like ('��1000%')
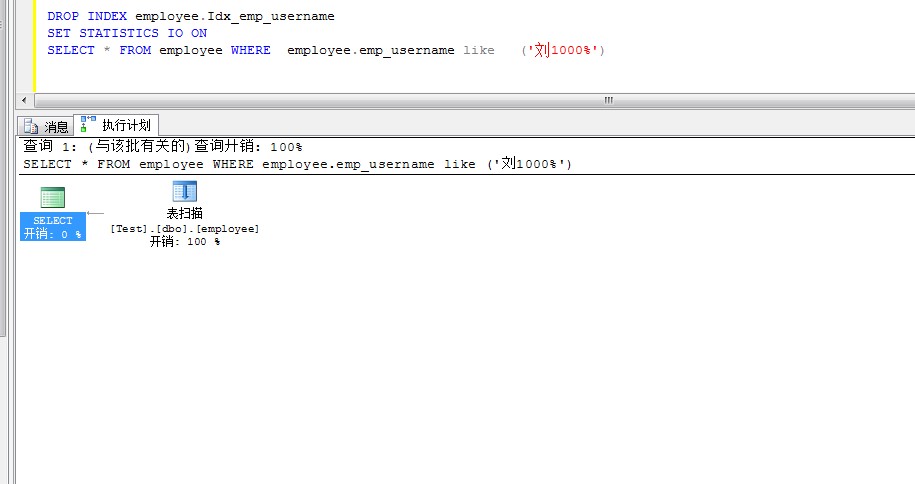
��Ϣ��
�� 'employee'��ɨ����� 1������ȡ 371 �Σ�������ȡ 0 �Σ�Ԥ�� 0 �Σ�lob ����ȡ 0 �Σ�lob ������ȡ 0 �Σ�lob Ԥ�� 0 �Ρ�
��������
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
SET STATISTICS IO ON
SELECT * FROM employee WHERE employee.emp_username like ( '��1000%');
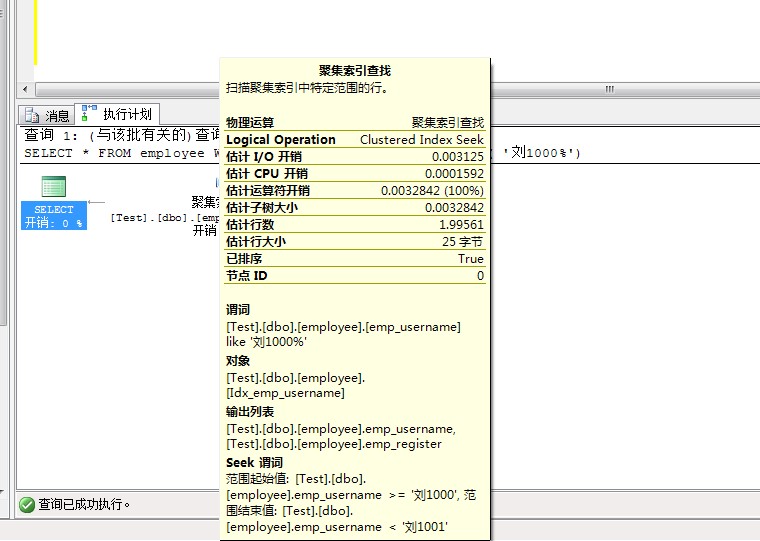
�� 'employee'��ɨ����� 1������ȡ 3 �Σ�������ȡ 0 �Σ�Ԥ�� 0 �Σ�lob ����ȡ 0 �Σ�lob ������ȡ 0 �Σ�lob Ԥ�� 0 �Ρ�
���Ϻܶ��Ż�������д����ѯ��Ҫʹ�� in like left ����ʵ�Լ����ֲ����¿�����ѯ�ƻ���һĻ��Ȼ�� ��
 ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����



