U濠电姰鍨归悥銏ゅ礃椤忓棙鍟4.7.37.56 闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷
U濠电姰鍨归悥銏ゅ礃椤忓棙鍟4.7.37.56 闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷 HD Tune Prov5.75 婵犳鍠氶幊鎾凰囬婧惧亾娴e啫鐨虹紒杈ㄥ浮閹虫顢涘鍏碱棏闂備胶绮〃鍫ュ箠閹捐鏄ラ柛鈩冪⊕閸嬪鏌ㄩ悤鍌涘
HD Tune Prov5.75 婵犳鍠氶幊鎾凰囬婧惧亾娴e啫鐨虹紒杈ㄥ浮閹虫顢涘鍏碱棏闂備胶绮〃鍫ュ箠閹捐鏄ラ柛鈩冪⊕閸嬪鏌ㄩ悤鍌涘 DiskGenius 濠电偞鍨堕幐濠氬箰妞嬪海绠旈柣鏂垮悑閸嬪鏌涢敂鍏煎5.2.1.941 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
DiskGenius 濠电偞鍨堕幐濠氬箰妞嬪海绠旈柣鏂垮悑閸嬪鏌涢敂鍏煎5.2.1.941 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 360闂佸搫顦遍崕鎰板垂椤栨埃鏋庨柕蹇嬪灮娑撳秹鏌嶉妷锕€澧柛鐔插亾v7.5.0.1460 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
360闂佸搫顦遍崕鎰板垂椤栨埃鏋庨柕蹇嬪灮娑撳秹鏌嶉妷锕€澧柛鐔插亾v7.5.0.1460 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� Cpu-Z濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌涜閹凤拷1.98.0 缂傚倸鍊峰ù鍥磿缂佹ḿ鐝跺┑鐘插暟閳绘梹銇勯幘璺烘瀾闁诲寒鍣i弻锝呂旂€n偄顏�
Cpu-Z濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌涜閹凤拷1.98.0 缂傚倸鍊峰ù鍥磿缂佹ḿ鐝跺┑鐘插暟閳绘梹銇勯幘璺烘瀾闁诲寒鍣i弻锝呂旂€n偄顏� 闂備胶鍘ч悘姘暦濮椻偓椤㈡瑩宕卞☉娆忎缓婵炶揪绲介崯顐g珶鐎n剛纾奸柣姗嗗亐閸嬫捇骞囨担鍛婃珒V15.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
闂備胶鍘ч悘姘暦濮椻偓椤㈡瑩宕卞☉娆忎缓婵炶揪绲介崯顐g珶鐎n剛纾奸柣姗嗗亐閸嬫捇骞囨担鍛婃珒V15.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� office2016婵犵數濮烽。浠嬪磻閹惧绠鹃柤濂割杺閸ゆ瑥霉閸忕厧濮嶇€规洘顨堢划姘跺绩瀹告19.5.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
office2016婵犵數濮烽。浠嬪磻閹惧绠鹃柤濂割杺閸ゆ瑥霉閸忕厧濮嶇€规洘顨堢划姘跺绩瀹告19.5.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂佸搫顦弲娑㈠箠濡ソ褰掓晸閿燂拷11闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯椤拷11.3.6.1870 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闂佸搫顦弲娑㈠箠濡ソ褰掓晸閿燂拷11闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯椤拷11.3.6.1870 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 360闂備胶枪缁绘劗绮旈悜钘夊瀭闁稿﹤鍎穎i5.3.0.5000 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
360闂備胶枪缁绘劗绮旈悜钘夊瀭闁稿﹤鍎穎i5.3.0.5000 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 360闂佽娴烽幊鎾凰囬鐐茬煑闊洦鎷嬬涵鍛杸婵ê鍚嬬紞宀勬⒑闂堚晝绉堕柟鍑ゆ嫹2022v13.1.5188.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
360闂佽娴烽幊鎾凰囬鐐茬煑闊洦鎷嬬涵鍛杸婵ê鍚嬬紞宀勬⒑闂堚晝绉堕柟鍑ゆ嫹2022v13.1.5188.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 闂傚倷妞掗崡鎶藉绩闁秴鍨傛繝濠傜墛椤ュ﹪鏌涜箛鎾村櫧妞ゆ柨娲弻锝夊煛鐎n偄顏�2022v9.1.6.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
闂傚倷妞掗崡鎶藉绩闁秴鍨傛繝濠傜墛椤ュ﹪鏌涜箛鎾村櫧妞ゆ柨娲弻锝夊煛鐎n偄顏�2022v9.1.6.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 闂備礁鎼Λ娆撳箰閹跺壙澶愬箻楠炲じ姹楅梻渚囧墮缁夊爼宕i敓锟�2021V5.81.0202.1111闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
闂備礁鎼Λ娆撳箰閹跺壙澶愬箻楠炲じ姹楅梻渚囧墮缁夊爼宕i敓锟�2021V5.81.0202.1111闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 闂傚⿴鍋勫ù鍌炲磻閸涙潙绠伴柨鐕傛嫹5.0婵犳鍠楅敃銏ゅ疾閼碱剛绠斿鑸靛姇绾偓闂佹悶鍎弲鐘绘偘閹剧粯鐓熸俊銈咁儐鐎氾拷5.0.80 濠德板€楁慨浼村礉瀹€鍕﹂柡鍐ㄧ墛閸嬪鏌ㄩ悤鍌涘
闂傚⿴鍋勫ù鍌炲磻閸涙潙绠伴柨鐕傛嫹5.0婵犳鍠楅敃銏ゅ疾閼碱剛绠斿鑸靛姇绾偓闂佹悶鍎弲鐘绘偘閹剧粯鐓熸俊銈咁儐鐎氾拷5.0.80 濠德板€楁慨浼村礉瀹€鍕﹂柡鍐ㄧ墛閸嬪鏌ㄩ悤鍌涘 濠电偞娼欓崥瀣晝閵忋倕鐭楅柨鐕傛嫹2022闂佽楠哥粻宥夊垂濞差亜鏄ユ繛鎴炴皑閸楁岸鏌i妶蹇斿8.0.9.11050 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
濠电偞娼欓崥瀣晝閵忋倕鐭楅柨鐕傛嫹2022闂佽楠哥粻宥夊垂濞差亜鏄ユ繛鎴炴皑閸楁岸鏌i妶蹇斿8.0.9.11050 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂備胶绮悧鏇炵暦椤掑嫨鈧啫鐣濋崟顒€娈炴俊銈忛檮椤戞瑥岣块幒鎳虫盯鎮ч崼婵嗘辈13.1.5闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
闂備胶绮悧鏇炵暦椤掑嫨鈧啫鐣濋崟顒€娈炴俊銈忛檮椤戞瑥岣块幒鎳虫盯鎮ч崼婵嗘辈13.1.5闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 photoshop cs6 濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘13.1.2.3 闂備胶枪缁绘劗绮旈悜钘夊瀭闁稿本绋撻埢鏃€銇勯幘璺烘瀾闁诲寒鍣i弻锝呂旂€n偄顏�
photoshop cs6 濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘13.1.2.3 闂備胶枪缁绘劗绮旈悜钘夊瀭闁稿本绋撻埢鏃€銇勯幘璺烘瀾闁诲寒鍣i弻锝呂旂€n偄顏�![Autodesk 3ds Max 2012闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾跺垝婵犳艾鐒垫い鎺嶇劍婵挳鏌熼幑鎰敿闁告﹩鍓熼弻锟犲磼濮橆厼绐涙繝鈷€鍕垫殰32&64]](https://p.e5n.com/up/2018-9/2018921055101508.png) Autodesk 3ds Max 2012闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾跺垝婵犳艾鐒垫い鎺嶇劍婵挳鏌熼幑鎰敿闁告﹩鍓熼弻锟犲磼濮橆厼绐涙繝鈷€鍕垫殰32&64]
Autodesk 3ds Max 2012闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾跺垝婵犳艾鐒垫い鎺嶇劍婵挳鏌熼幑鎰敿闁告﹩鍓熼弻锟犲磼濮橆厼绐涙繝鈷€鍕垫殰32&64] CAD2007闂備胶枪缁绘劗绮旈悜钘夊瀭闁稿本绋撻埢鏃€銇勯幘璺烘瀾闁诲寒鍣i弻锝呂旂€n偄顏�
CAD2007闂備胶枪缁绘劗绮旈悜钘夊瀭闁稿本绋撻埢鏃€銇勯幘璺烘瀾闁诲寒鍣i弻锝呂旂€n偄顏� vc闂佸搫顦弲婊堝礉濮椻偓閵嗕線骞嬮悙鏉戝妳闂佽法鍣﹂幏锟�2019闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯椤拷2019.3.2(32&64濠电偠鎻紞鍥箯閿燂拷)
vc闂佸搫顦弲婊堝礉濮椻偓閵嗕線骞嬮悙鏉戝妳闂佽法鍣﹂幏锟�2019闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯椤拷2019.3.2(32&64濠电偠鎻紞鍥箯閿燂拷) .NET Framework 4.8闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷4.8.3646
.NET Framework 4.8闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷4.8.3646 QQ2022v9.5.6.28129 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
QQ2022v9.5.6.28129 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闁诲海鏁婚崑濠囧窗閺囩喓鈹嶅┑鐘叉处閸嬨劌霉閿濆懎鏆欏鐟邦儔閺岋絽螖鐎n偄顏�2022v3.5.0.44 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
闁诲海鏁婚崑濠囧窗閺囩喓鈹嶅┑鐘叉处閸嬨劌霉閿濆懎鏆欏鐟邦儔閺岋絽螖鐎n偄顏�2022v3.5.0.44 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 闂備礁鎲¢〃鍛村疮閻楀牊娅犲ù鍏兼綑绾偓闂佸搫璇炵仦鑺ユ珒闁诲氦顫夐幃鍫曞磿閹殿喚绀婇柡鍐ㄧ墢瀹撲線鏌涢幇顓炵祷闂佹壆婀�9.02.02N 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闂備礁鎲¢〃鍛村疮閻楀牊娅犲ù鍏兼綑绾偓闂佸搫璇炵仦鑺ユ珒闁诲氦顫夐幃鍫曞磿閹殿喚绀婇柡鍐ㄧ墢瀹撲線鏌涢幇顓炵祷闂佹壆婀�9.02.02N 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 QT闂佽崵濮村ù鍌炲矗閸愵喗鍋傜紒鍌︽嫹4.6.80.18262闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
QT闂佽崵濮村ù鍌炲矗閸愵喗鍋傜紒鍌︽嫹4.6.80.18262闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 濠碉紕鍋涢鍥磻濡崵鈹嶉柨鐕傛嫹2018V6.2.0700 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
濠碉紕鍋涢鍥磻濡崵鈹嶉柨鐕傛嫹2018V6.2.0700 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 濠电偞鎸诲銊︽叏瀹勬噴鍝勵吋閸♀晜效闂佺粯鍔橀崺鏍姳閻樼數纾介柛鎰綖缁ㄧ厧霉閸忓吋宕岄柡灞界墦閹稿﹥寰勫畝濠佺礈
濠电偞鎸诲銊︽叏瀹勬噴鍝勵吋閸♀晜效闂佺粯鍔橀崺鏍姳閻樼數纾介柛鎰綖缁ㄧ厧霉閸忓吋宕岄柡灞界墦閹稿﹥寰勫畝濠佺礈 濠德板€楁慨鐢稿垂閸ф鐓橀柛顐ゅ枔閳绘棃骞栨潏鍓ф偧闁糕晛妫濋弻鈩冨緞閸℃ぞ澹曠紓鍌氬€烽懗鍓佹崲濠靛瑙︽い鎰╁焺閸ゆ霉閿濆牜娼愮紒鐙呮嫹
濠德板€楁慨鐢稿垂閸ф鐓橀柛顐ゅ枔閳绘棃骞栨潏鍓ф偧闁糕晛妫濋弻鈩冨緞閸℃ぞ澹曠紓鍌氬€烽懗鍓佹崲濠靛瑙︽い鎰╁焺閸ゆ霉閿濆牜娼愮紒鐙呮嫹 闂備焦鍎崇换鎴﹀礉閺嵭跨細闁告劦鍠栭崒銊╂煟閺冨倹鐒块柛鈺嬫嫹2
闂備焦鍎崇换鎴﹀礉閺嵭跨細闁告劦鍠栭崒銊╂煟閺冨倹鐒块柛鈺嬫嫹2 濠电偛顕慨浼村磿閺屻儱绠┑鐘崇閸庡秹鏌涢弴銊ュ箻婵炲鍨介弻娑橆潩閻愵剙顏�
濠电偛顕慨浼村磿閺屻儱绠┑鐘崇閸庡秹鏌涢弴銊ュ箻婵炲鍨介弻娑橆潩閻愵剙顏� 闂備礁鎼ˇ顐﹀磻閹剧粯鐓欑痪鏉款槹鐎氾拷5闂佽崵濮嶅鍥╂殸闂佸憡锕幏锟�
闂備礁鎼ˇ顐﹀磻閹剧粯鐓欑痪鏉款槹鐎氾拷5闂佽崵濮嶅鍥╂殸闂佸憡锕幏锟� H1Z1濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘
H1Z1濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘 闂佽瀛╃粙蹇涘磹閺囥垺鍎楁繝闈涱儏缁犳艾鈹戦悩鍙夊窛闁圭》鎷�3
闂佽瀛╃粙蹇涘磹閺囥垺鍎楁繝闈涱儏缁犳艾鈹戦悩鍙夊窛闁圭》鎷�3 濠电偞鍨堕幐鎼佀囬幎鏂ょ稏婵°倐鍋撻悡銈夋煠绾板崬澧い銉︻殘缁辨帗寰勬繝鍕懷囨煕鎼淬垺灏︽慨濠傘偢閺佹捇鏁撻敓锟�6闂備胶鎳撻悺銊╂晝閵忕姈锝夋晜閻e备鏋欓柣搴秵娴滄粓鎮楅敓锟�
濠电偞鍨堕幐鎼佀囬幎鏂ょ稏婵°倐鍋撻悡銈夋煠绾板崬澧い銉︻殘缁辨帗寰勬繝鍕懷囨煕鎼淬垺灏︽慨濠傘偢閺佹捇鏁撻敓锟�6闂備胶鎳撻悺銊╂晝閵忕姈锝夋晜閻e备鏋欓柣搴秵娴滄粓鎮楅敓锟� 濠电偠鎻徊浠嬫倶濠靛绠犻柨鐔哄Т閻銇勯幒鍡椾壕闂佽桨绶ら幏锟�8:闂備胶绮划鎾汇€傞敃鍌氳埞妞ゆ帒瀚粻锝嗕繆椤栨碍璐¢柟闈╂嫹3
濠电偠鎻徊浠嬫倶濠靛绠犻柨鐔哄Т閻銇勯幒鍡椾壕闂佽桨绶ら幏锟�8:闂備胶绮划鎾汇€傞敃鍌氳埞妞ゆ帒瀚粻锝嗕繆椤栨碍璐¢柟闈╂嫹3 闂備礁鎲¢懝楣冩偋閹捐闂柛鎾楀嫬鏅抽梺鍛婁緱閸欏骸危閿燂拷5:婵°倗濮烽崑鐘茬暦闂堟党娑㈡晸閿燂拷
闂備礁鎲¢懝楣冩偋閹捐闂柛鎾楀嫬鏅抽梺鍛婁緱閸欏骸危閿燂拷5:婵°倗濮烽崑鐘茬暦闂堟党娑㈡晸閿燂拷 婵犵數鍋涢弻宀勫礋椤愩倕鎼搁梻浣告啞椤﹀綊濡堕崱娆戞碀婵犵妲呴崹顏堝礈濠靛牃鍋撳鐐2
婵犵數鍋涢弻宀勫礋椤愩倕鎼搁梻浣告啞椤﹀綊濡堕崱娆戞碀婵犵妲呴崹顏堝礈濠靛牃鍋撳鐐2 闂備礁鎼崯顐︻敄閸緷褰掑幢濡顫″銈嗘煥閻忔繈宕滈敓锟�
闂備礁鎼崯顐︻敄閸緷褰掑幢濡顫″銈嗘煥閻忔繈宕滈敓锟� 闂備礁鎼鍕矆娓氣偓楠炴牞顦虫い锔垮嵆閹瑩鎳滈悽鐢垫碀18
闂備礁鎼鍕矆娓氣偓楠炴牞顦虫い锔垮嵆閹瑩鎳滈悽鐢垫碀18 缂傚倷妞掗懗鍫曞磻濞戞瑦鍙忛煫鍥ㄦ礈閻捇鏌熸潏鍓у埌缂佹鎷�
缂傚倷妞掗懗鍫曞磻濞戞瑦鍙忛煫鍥ㄦ礈閻捇鏌熸潏鍓у埌缂佹鎷� F1 2015
F1 2015 闂備胶鎳撻悺銊╁垂閻熸壋鏋旈柟瀵稿仧閳绘棃鏌″搴′簼婵炲拑鎷�1.8.2
闂備胶鎳撻悺銊╁垂閻熸壋鏋旈柟瀵稿仧閳绘棃鏌″搴′簼婵炲拑鎷�1.8.2 婵犵數鍋涢ˇ杈ㄦ櫠濡や礁鍨旀繛宸簼閸嬶繝鏌i幇顓烆棆闁艰鎷�
婵犵數鍋涢ˇ杈ㄦ櫠濡や礁鍨旀繛宸簼閸嬶繝鏌i幇顓烆棆闁艰鎷� 濠德板€栭妵婊堝磿閺夋垹鏆﹂柨鐕傛嫹:婵犵數鍋涢顓㈠礂濡洅鎺楁晸閿燂拷
濠德板€栭妵婊堝磿閺夋垹鏆﹂柨鐕傛嫹:婵犵數鍋涢顓㈠礂濡洅鎺楁晸閿燂拷 闂備礁鎼€氼噣宕伴幘璇茬柧妞ゆ劧绲剧紞鍥煟閻旂厧浜伴柡鍡嫹
闂備礁鎼€氼噣宕伴幘璇茬柧妞ゆ劧绲剧紞鍥煟閻旂厧浜伴柡鍡嫹 闂備礁鎼悧鍐磻閹剧粯鐓曟慨姗嗗墯閹癸綁鏌℃担瑙勫鞍婵炶壈顕ц灒閹煎瓨鎸告禍楣冩煕閺嶎偄绶ㄩ梻浣虹帛椤ㄦ劙骞忛敓锟�
闂備礁鎼悧鍐磻閹剧粯鐓曟慨姗嗗墯閹癸綁鏌℃担瑙勫鞍婵炶壈顕ц灒閹煎瓨鎸告禍楣冩煕閺嶎偄绶ㄩ梻浣虹帛椤ㄦ劙骞忛敓锟� 闂備礁鎼崐绋棵洪敃鈧嵄闁跨噦鎷�5:缂傚倸鍊稿ú銈囪姳婵傚憡鈷旈柛鏇ㄥ灠濡ê螞妫颁浇鍏岄柣鐕佸灦閺岋綁鏁愯箛鏂款伓
闂備礁鎼崐绋棵洪敃鈧嵄闁跨噦鎷�5:缂傚倸鍊稿ú銈囪姳婵傚憡鈷旈柛鏇ㄥ灠濡ê螞妫颁浇鍏岄柣鐕佸灦閺岋綁鏁愯箛鏂款伓 濠电偞鍨堕幐鎼佀囬姣懓螖閸曨厾鏉搁梺璺ㄥ櫐閹凤拷12濠电姷鏁搁崑妯肩矆娴h鍙忛煫鍥ㄧ☉缁€澶愭煟濡绲荤紒璁崇窔閺岋絽螖鐎n偄顏�
濠电偞鍨堕幐鎼佀囬姣懓螖閸曨厾鏉搁梺璺ㄥ櫐閹凤拷12濠电姷鏁搁崑妯肩矆娴h鍙忛煫鍥ㄧ☉缁€澶愭煟濡绲荤紒璁崇窔閺岋絽螖鐎n偄顏� 濠电儑绲藉ù鍕崲濠靛姹查弶鍫涘妿閳绘洟鎮楅敐搴℃灈婵炲拑缍侀弻锟犲醇椤掍礁顏�14濠电姷鏁搁崑妯肩矆娴h鍙忛煫鍥ㄧ☉缁€澶愭煟濡绲荤紒璁崇窔閺岋絽螖鐎n偄顏�
濠电儑绲藉ù鍕崲濠靛姹查弶鍫涘妿閳绘洟鎮楅敐搴℃灈婵炲拑缍侀弻锟犲醇椤掍礁顏�14濠电姷鏁搁崑妯肩矆娴h鍙忛煫鍥ㄧ☉缁€澶愭煟濡绲荤紒璁崇窔閺岋絽螖鐎n偄顏� 闂傚倸鍊搁崯顖溾偓绗涘棎浜瑰〒姘e亾妤犵偛绻橀弫鎾绘晸閿燂拷:闂備胶枪缁诲牓宕濋幋婵佺細濞村吋娼欑粻锝嗕繆椤栨碍璐¢柟闈╂嫹
闂傚倸鍊搁崯顖溾偓绗涘棎浜瑰〒姘e亾妤犵偛绻橀弫鎾绘晸閿燂拷:闂備胶枪缁诲牓宕濋幋婵佺細濞村吋娼欑粻锝嗕繆椤栨碍璐¢柟闈╂嫹 闂佹眹鍩勯崹杈╂崲閸屾鐟拔旈崨顓犵潉闂佸搫鐗撳ḿ褔寮敓锟�2闁诲海鏁婚。锕傛倿閿曗偓閿曘垽宕堕浣告畬闂佽法鍣﹂幏锟�
闂佹眹鍩勯崹杈╂崲閸屾鐟拔旈崨顓犵潉闂佸搫鐗撳ḿ褔寮敓锟�2闁诲海鏁婚。锕傛倿閿曗偓閿曘垽宕堕浣告畬闂佽法鍣﹂幏锟� 闂備浇銆€閸嬫挻銇勯弽銊ф噮閻㈩垱鐩幃妤冩喆閸曨厾鐤勯梺鍦归悥鐓庣暦閻樼粯鏅搁柨鐕傛嫹(Alipay)V10.2.53.7000 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂備浇銆€閸嬫挻銇勯弽銊ф噮閻㈩垱鐩幃妤冩喆閸曨厾鐤勯梺鍦归悥鐓庣暦閻樼粯鏅搁柨鐕傛嫹(Alipay)V10.2.53.7000 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂備浇鐨崟顐㈠Б闁诲氦顫夋繛濠傜暦閻戣棄绾ч柟绋挎捣椤╊參鏌f惔婵堢シ濠㈢懓鐗撳畷娲晸閿燂拷2022V15.12.10 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗嗙粻銉╂倵閿濆骸浜濈紒銊﹀哺閺岋絽螖鐎n偄顏�
闂備浇鐨崟顐㈠Б闁诲氦顫夋繛濠傜暦閻戣棄绾ч柟绋挎捣椤╊參鏌f惔婵堢シ濠㈢懓鐗撳畷娲晸閿燂拷2022V15.12.10 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗嗙粻銉╂倵閿濆骸浜濈紒銊﹀哺閺岋絽螖鐎n偄顏� 闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞屽墯缁绘盯鏁愰崰銏╀邯閹潡宕掑┃鎯т壕妤犵偛鐏濋悘顏堟煕閳哄倻銆掔紒顔规櫊閹偓闁跨噦鎷�10.8.40闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞屽墯缁绘盯鏁愰崰銏╀邯閹潡宕掑┃鎯т壕妤犵偛鐏濋悘顏堟煕閳哄倻銆掔紒顔规櫊閹偓闁跨噦鎷�10.8.40闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂備椒绱徊浠嬪箠濮椻偓閸┾偓妞ゆ帊鐒﹂埛鎺旂磽瀹ュ拋妯€妤犵偛绉堕埀顒婄秵閸嬪懐鑺卞鑸靛€垫鐐茬仢閻忣亪鏌涢埡鍌溿€掔紒顔规櫊閹偓闁跨噦鎷�5.6.9 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂備椒绱徊浠嬪箠濮椻偓閸┾偓妞ゆ帊鐒﹂埛鎺旂磽瀹ュ拋妯€妤犵偛绉堕埀顒婄秵閸嬪懐鑺卞鑸靛€垫鐐茬仢閻忣亪鏌涢埡鍌溿€掔紒顔规櫊閹偓闁跨噦鎷�5.6.9 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂備礁鎲¢〃鍛村疮閾忣偆顩插ù鐓庣摠閸庢鏌曟径鍫濆婵″弶娲熼弻锟犲醇濠靛熆銏犫攽椤旀儳澹僷pv4.5.1闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闂備礁鎲¢〃鍛村疮閾忣偆顩插ù鐓庣摠閸庢鏌曟径鍫濆婵″弶娲熼弻锟犲醇濠靛熆銏犫攽椤旀儳澹僷pv4.5.1闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 p2psearcher闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�7.3 闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞屽墴閺岋絽螖鐎n偄顏�
p2psearcher闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�7.3 闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞屽墴閺岋絽螖鐎n偄顏� 闂傚倷妞掗崡鎶剿夐幘鍨涘亾濮橆剛效婵☆偄鎳樺畷妤呭川椤栵絽鏁�2022闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜斿畷鐑芥晸閿燂拷11.0.8 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
闂傚倷妞掗崡鎶剿夐幘鍨涘亾濮橆剛效婵☆偄鎳樺畷妤呭川椤栵絽鏁�2022闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜斿畷鐑芥晸閿燂拷11.0.8 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 闂備胶绮悧鏇炵暦椤掑嫨鈧啫鐣濋崟顒€娈為梺缁樺灦閿氭い銈勭窔閺岋繝宕奸敐鍡╀哗婵犫拃鍕垫蕉13.1.0
闂備胶绮悧鏇炵暦椤掑嫨鈧啫鐣濋崟顒€娈為梺缁樺灦閿氭い銈勭窔閺岋繝宕奸敐鍡╀哗婵犫拃鍕垫蕉13.1.0 闂備浇鐨崟顐㈠Б闁诲海鎳撻悿鍥Φ閹扮増鐒肩€广儱娲ゅ锟�7.13.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂備浇鐨崟顐㈠Б闁诲海鎳撻悿鍥Φ閹扮増鐒肩€广儱娲ゅ锟�7.13.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闁荤喐绮堥崡铏閸洘鍋傞柛顐f礀缁€鍌炴煕椤愮姴鍔滈柡浣烘篂6.9.0 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗嗙粻銉╂倵閿濆骸浜濈紒銊﹀哺閺岋絽螖鐎n偄顏�
闁荤喐绮堥崡铏閸洘鍋傞柛顐f礀缁€鍌炴煕椤愮姴鍔滈柡浣烘篂6.9.0 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗嗙粻銉╂倵閿濆骸浜濈紒銊﹀哺閺岋絽螖鐎n偄顏� 闂備胶鍘ч悘姘暦濮椻偓椤㈡瑩宕卞☉妯碱槷闂侀潧饪甸梽鍕倵閻烇拷9.11.5 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂備胶鍘ч悘姘暦濮椻偓椤㈡瑩宕卞☉妯碱槷闂侀潧饪甸梽鍕倵閻烇拷9.11.5 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 濠电偞鍨跺Λ鎴︽⒔閸曨倠娑樜旈崘褏鍓ㄩ棅顐㈡处閸戝綊宕靛☉銏$厱闊洦鎸惧暩闂佹悶鍔岄崐鍧楀箖瑜斿畷濂告偄閸涘﹤顏皏11.5.5.153 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
濠电偞鍨跺Λ鎴︽⒔閸曨倠娑樜旈崘褏鍓ㄩ棅顐㈡处閸戝綊宕靛☉銏$厱闊洦鎸惧暩闂佹悶鍔岄崐鍧楀箖瑜斿畷濂告偄閸涘﹤顏皏11.5.5.153 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� QQ闂傚倸鍊搁崯顐﹀箠閹炬椿鏁嬪ù鍏兼綑闂傤垶鏌嶉悜妯哄挤pV7.7.1.910 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
QQ闂傚倸鍊搁崯顐﹀箠閹炬椿鏁嬪ù鍏兼綑闂傤垶鏌嶉悜妯哄挤pV7.7.1.910 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂備胶顢婂▍鏇犳暜婵犲倐褎寰勯幇顓炰患闂佸憡渚楅崢浠嬪磿閺冨牊鐓曟慨妯煎帶閸樻悂鏌涢弮鍌氬ppv7.1.5 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
闂備胶顢婂▍鏇犳暜婵犲倐褎寰勯幇顓炰患闂佸憡渚楅崢浠嬪磿閺冨牊鐓曟慨妯煎帶閸樻悂鏌涢弮鍌氬ppv7.1.5 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 闂佽崵濮嶉崶鑸殿棖闂佺ǹ顑戠徊鍧楀箯閻樺灚濯奸柛鎰絻椤嚰pp闂備礁鎼崐瑙勭珶閸℃ɑ娅犳俊銈呮噹鐎氬鏌ㄩ悤鍌涘20227.9.186 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂佽崵濮嶉崶鑸殿棖闂佺ǹ顑戠徊鍧楀箯閻樺灚濯奸柛鎰絻椤嚰pp闂備礁鎼崐瑙勭珶閸℃ɑ娅犳俊銈呮噹鐎氬鏌ㄩ悤鍌涘20227.9.186 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 婵°倗濮烽崑娑㈠疮閸ф鍋╅柕濞у嫬鐝版繛杈剧悼鏋柣鎾寸墵閹鎮烽幍鏂ュ亾閿曞倹鐓熼柣鎰级椤ワ繝鏌涚仦鍛婃珶9.1.0.1 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
婵°倗濮烽崑娑㈠疮閸ф鍋╅柕濞у嫬鐝版繛杈剧悼鏋柣鎾寸墵閹鎮烽幍鏂ュ亾閿曞倹鐓熼柣鎰级椤ワ繝鏌涚仦鍛婃珶9.1.0.1 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 婵犵數鍋涢顓㈠礂濮椻偓閸┾偓妞ゆ帊妞掓禍銏ゆ煟閿曗偓椤﹂潧鐣峰璺哄窛濠电姴鍋嗛弶褰掓⒑閸濆嫮澧f繛鍜冪稻閺呭爼鏁撻敓锟�(e婵犵數鍋涢顓㈠礂濮椻偓閸┾偓妞ゆ帊妞掓禍銏ゆ煕瀹€瀣)8.71 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
婵犵數鍋涢顓㈠礂濮椻偓閸┾偓妞ゆ帊妞掓禍銏ゆ煟閿曗偓椤﹂潧鐣峰璺哄窛濠电姴鍋嗛弶褰掓⒑閸濆嫮澧f繛鍜冪稻閺呭爼鏁撻敓锟�(e婵犵數鍋涢顓㈠礂濮椻偓閸┾偓妞ゆ帊妞掓禍銏ゆ煕瀹€瀣)8.71 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 濠电偞鍨堕幐鑽ゅ垝瀹ュ绠查柨婵嗘处鐎氭艾霉閿濆毥褰掓偂閺嵮€妲堥柟鎯ь嚟閻鏌熼惂鍝ョМ闁诡喖鐖煎畷鍗烆潩椤掆偓娴滐拷4.0.5 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
濠电偞鍨堕幐鑽ゅ垝瀹ュ绠查柨婵嗘处鐎氭艾霉閿濆毥褰掓偂閺嵮€妲堥柟鎯ь嚟閻鏌熼惂鍝ョМ闁诡喖鐖煎畷鍗烆潩椤掆偓娴滐拷4.0.5 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 濠电偞鍨堕幖鈺呭矗閸愵喖绠洪弶鍫氭櫆鐎氭艾霉閿濆毥褰掓偂閺嶎偆纾煎璺哄瘨閸ゆ瑥鈹戦瑙勬珚闁诡喖鐖煎畷鍗烆潩椤掆偓娴滃爼鏌℃径灞藉壉闁割煈鍨伴埢搴ㄦ晸閿燂拷6.02.010 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
濠电偞鍨堕幖鈺呭矗閸愵喖绠洪弶鍫氭櫆鐎氭艾霉閿濆毥褰掓偂閺嶎偆纾煎璺哄瘨閸ゆ瑥鈹戦瑙勬珚闁诡喖鐖煎畷鍗烆潩椤掆偓娴滃爼鏌℃径灞藉壉闁割煈鍨伴埢搴ㄦ晸閿燂拷6.02.010 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 闂備礁鎲¢〃鍛存煀閿濆洦顐界€规洖娲︾€氭艾霉閿濆毥褰掓偂閺嶎厽鍊堕煫鍥ㄦ尵缁犲鏌涢敐澶岀暫妤犵偛绉堕埀顒婄秵閸嬪懐鑺卞鑸电厽闁绘劕寮堕ˉ锟犳煕鐏炶濡芥繛纰变邯椤㈡稑鈻庨幇闈涗缓3.2.4 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂備礁鎲¢〃鍛存煀閿濆洦顐界€规洖娲︾€氭艾霉閿濆毥褰掓偂閺嶎厽鍊堕煫鍥ㄦ尵缁犲鏌涢敐澶岀暫妤犵偛绉堕埀顒婄秵閸嬪懐鑺卞鑸电厽闁绘劕寮堕ˉ锟犳煕鐏炶濡芥繛纰变邯椤㈡稑鈻庨幇闈涗缓3.2.4 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 缂傚倷绀侀崐鍝ユ崲閹邦喚纾介柟鎹愵嚙缁€鍐╃節婵犲倸顏紓宥嗗灥鑿愰柛銉╊棑绾惧潡鏌℃担闈涒偓妤冨垝閸儲鍊锋い鎺嗗亾妞ゃ倓绶氶弻锟犲醇閻旀悶浠㈤梺鐟扳偓鐔跺惈闁诡喗澹嗘禒锔剧驳鐎n亝鍊曢梻浣筋潐閹告娊藟閹炬椿鏁傞柨鐕傛嫹2.3.4 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
缂傚倷绀侀崐鍝ユ崲閹邦喚纾介柟鎹愵嚙缁€鍐╃節婵犲倸顏紓宥嗗灥鑿愰柛銉╊棑绾惧潡鏌℃担闈涒偓妤冨垝閸儲鍊锋い鎺嗗亾妞ゃ倓绶氶弻锟犲醇閻旀悶浠㈤梺鐟扳偓鐔跺惈闁诡喗澹嗘禒锔剧驳鐎n亝鍊曢梻浣筋潐閹告娊藟閹炬椿鏁傞柨鐕傛嫹2.3.4 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂備礁鎼€氼參骞愰幖浣告槬婵°倓鐒︽刊瀛樼節婵犲倹锛嶆繛鍏煎笒铻為柣妤€鐗嗛悘銉ヮ熆閸忓浜鹃梺鍝勵槸閻楀﹪宕i—绉�4.1.16闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂備礁鎼€氼參骞愰幖浣告槬婵°倓鐒︽刊瀛樼節婵犲倹锛嶆繛鍏煎笒铻為柣妤€鐗嗛悘銉ヮ熆閸忓浜鹃梺鍝勵槸閻楀﹪宕i—绉�4.1.16闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 濠电偞鍨堕幖鈺呭储閻撳篃鐟拔旈埀顒勵敊韫囨稑唯闁靛闄勯悵婊堟⒒娴e搫浜鹃柛搴°偢閵嗕線骞嬮敃鈧粻銉╂倵閿濆骸浜濈紒銊﹀哺濮婃椽鎮欓鈧崝鑸点亜閵忊€冲綘ppV7.0.1.2.5 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
濠电偞鍨堕幖鈺呭储閻撳篃鐟拔旈埀顒勵敊韫囨稑唯闁靛闄勯悵婊堟⒒娴e搫浜鹃柛搴°偢閵嗕線骞嬮敃鈧粻銉╂倵閿濆骸浜濈紒銊﹀哺濮婃椽鎮欓鈧崝鑸点亜閵忊€冲綘ppV7.0.1.2.5 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 濠电偞鍨堕幖鈺呭储閻撳篃鐟拔旈崨顔惧弰闂佽鍨堕崑濠囧绩娴犲鐓欓梻鍫熶緱閸庢劖绻濊閸嬫捇姊绘担鍝勪壕闁稿骸銈搁妴渚€骞嬮悩顐壕妤犵偛鐏濋悘顏堟煕閳哄倻銆掔紒顔规櫊閺佹捇鏁撻敓锟�7.2.5 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
濠电偞鍨堕幖鈺呭储閻撳篃鐟拔旈崨顔惧弰闂佽鍨堕崑濠囧绩娴犲鐓欓梻鍫熶緱閸庢劖绻濊閸嬫捇姊绘担鍝勪壕闁稿骸銈搁妴渚€骞嬮悩顐壕妤犵偛鐏濋悘顏堟煕閳哄倻銆掔紒顔规櫊閺佹捇鏁撻敓锟�7.2.5 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 闂備胶鍘ч悘姘暦濮椻偓椤㈡瑩宕卞☉娆忎粡闁瑰吋鐣崝宀勩€冨▎鎾崇骇闁割偅绻傜紞鏍ㄦ叏閻熼偊妯€妤犵偛绉堕埀顒婄秵閸嬪懐鑺卞鑸电厽婵°倐鍋撴繝鈧敓锟�2.3.0.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
闂備胶鍘ч悘姘暦濮椻偓椤㈡瑩宕卞☉娆忎粡闁瑰吋鐣崝宀勩€冨▎鎾崇骇闁割偅绻傜紞鏍ㄦ叏閻熼偊妯€妤犵偛绉堕埀顒婄秵閸嬪懐鑺卞鑸电厽婵°倐鍋撴繝鈧敓锟�2.3.0.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 闂備礁鎲″Λ浣轰焊椤忓牆鍨傞柛顐f礀閻愬﹪鏌曡箛鏇炐ラ柡鍡╁弮閺岋繝宕掑┑鎰秷濡炪倖甯楃划鎾诲箖瑜斿畷濂告偄婵傚婢掓繝鐢靛仦閹搁箖顢旈敓锟�1.2.1闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闂備礁鎲″Λ浣轰焊椤忓牆鍨傞柛顐f礀閻愬﹪鏌曡箛鏇炐ラ柡鍡╁弮閺岋繝宕掑┑鎰秷濡炪倖甯楃划鎾诲箖瑜斿畷濂告偄婵傚婢掓繝鐢靛仦閹搁箖顢旈敓锟�1.2.1闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 濠德板€栭妵婊堝磿閻㈢ǹ围闁圭ǹ绨烘禒鍫ユ煏婵炵偓娅呮い銊︾懇瀵爼鍩¢崒婧炬闁诲骸鐏氶悡鈥愁嚕椤曗偓閹晝绱掑鍡忓亾濞嗘挻鈷戦柛濠勫枎閸氬綊鏌i幘宕囧煟闁诡啫鍥ч敜闁跨噦鎷�7.8.0.0闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
濠德板€栭妵婊堝磿閻㈢ǹ围闁圭ǹ绨烘禒鍫ユ煏婵炵偓娅呮い銊︾懇瀵爼鍩¢崒婧炬闁诲骸鐏氶悡鈥愁嚕椤曗偓閹晝绱掑鍡忓亾濞嗘挻鈷戦柛濠勫枎閸氬綊鏌i幘宕囧煟闁诡啫鍥ч敜闁跨噦鎷�7.8.0.0闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 婵犵绱曢崑娑氱矓閼稿灚娅犻柟绋块缁剁偟鎲告惔銊ュ瀭妞ゆ帒瀚壕浠嬫⒒閸喓鈯曟い銏犵Ч閺屾稖绠涚€n亜顬夊┑鈥冲级閸ㄥ灝顕f导瀛樻櫢闁跨噦鎷�1.0.91 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
婵犵绱曢崑娑氱矓閼稿灚娅犻柟绋块缁剁偟鎲告惔銊ュ瀭妞ゆ帒瀚壕浠嬫⒒閸喓鈯曟い銏犵Ч閺屾稖绠涚€n亜顬夊┑鈥冲级閸ㄥ灝顕f导瀛樻櫢闁跨噦鎷�1.0.91 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂備線娼荤粻鎾汇€傞敂鍓х當闁告稒娼欓弰銉╁箹鏉堝墽鎮肩€规洘鍔欓弻娑㈠箣閻愭惌娼¢梺閫炲苯澧€规洘鍞搁梻浣虹帛椤ㄦ劙骞忛敓锟�1.6.3 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闂備線娼荤粻鎾汇€傞敂鍓х當闁告稒娼欓弰銉╁箹鏉堝墽鎮肩€规洘鍔欓弻娑㈠箣閻愭惌娼¢梺閫炲苯澧€规洘鍞搁梻浣虹帛椤ㄦ劙骞忛敓锟�1.6.3 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 闂佽崵鍠嶇粈渚€骞婇幇鏉挎瀬闁规儼濮ら崵鍌炴煛閸愩劌鈧湱绮堥敓锟�1.325.157 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂佽崵鍠嶇粈渚€骞婇幇鏉挎瀬闁规儼濮ら崵鍌炴煛閸愩劌鈧湱绮堥敓锟�1.325.157 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂備線娼荤拋锝囧緤妤e啫鍑犻柣鏂挎憸閻濊埖銇勯幇鍓佺ɑ鐞氭繈姊哄ú璇插箲闁搞劏妫勯埢鏃堟晜閸撗咃紲闂佸湱銆嬮幏锟�4.2.1 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂備線娼荤拋锝囧緤妤e啫鍑犻柣鏂挎憸閻濊埖銇勯幇鍓佺ɑ鐞氭繈姊哄ú璇插箲闁搞劏妫勯埢鏃堟晜閸撗咃紲闂佸湱銆嬮幏锟�4.2.1 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂傚倷绶¢崜锕傚窗閺嶎厼桅闁跨噦鎷�3D闂備礁缍婂ḿ褔顢栭崱娑欏亯闁跨噦鎷�1.0.9闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂傚倷绶¢崜锕傚窗閺嶎厼桅闁跨噦鎷�3D闂備礁缍婂ḿ褔顢栭崱娑欏亯闁跨噦鎷�1.0.9闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鍠氬〒鑽も偓骞垮劚濞层倝鍩涢弽褜鐔嗛柛顐㈡鐎氼剟鎮樺☉銏$厱鐎广儱顦板☉褎淇婂Δ瀣2濠殿喗甯楃粙鎺楀垂鐠鸿 鏋旀い鎰剁畱缁秹鏌¢崼銉︽锭闁轰讲鏅涜彁闁搞儴娉涢弸鐔兼煛娴f悶鍋㈤柟顔ㄥ洤鎹堕柨鐕傛嫹1.9.5 闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷
闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鍠氬〒鑽も偓骞垮劚濞层倝鍩涢弽褜鐔嗛柛顐㈡鐎氼剟鎮樺☉銏$厱鐎广儱顦板☉褎淇婂Δ瀣2濠殿喗甯楃粙鎺楀垂鐠鸿 鏋旀い鎰剁畱缁秹鏌¢崼銉︽锭闁轰讲鏅涜彁闁搞儴娉涢弸鐔兼煛娴f悶鍋㈤柟顔ㄥ洤鎹堕柨鐕傛嫹1.9.5 闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷 濠电偞鍨跺Λ浣广仈閹间礁鍑犻柣鏃傚劋閸熷潡鏌熺粙鎸庢崳闁糕晪鎷�2v1.0.150闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
濠电偞鍨跺Λ浣广仈閹间礁鍑犻柣鏃傚劋閸熷潡鏌熺粙鎸庢崳闁糕晪鎷�2v1.0.150闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 濠电儑绲藉ú锔炬崲閸屾氨鏆﹀┑鍌氭啞婵増绻濋棃娑欘棞婵$儑鎷�3闂備礁鎼崯鐗堢箾閳ь剚淇婇悙顒併仢闁哄矉绠撻幊锟犲Χ閸パ冪翻闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯椤拷2.0.0.1 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
濠电儑绲藉ú锔炬崲閸屾氨鏆﹀┑鍌氭啞婵増绻濋棃娑欘棞婵$儑鎷�3闂備礁鎼崯鐗堢箾閳ь剚淇婇悙顒併仢闁哄矉绠撻幊锟犲Χ閸パ冪翻闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯椤拷2.0.0.1 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂備礁鎲¢悷杈╃礊閳ь剚銇勯敐鍕祮闁瑰磭鍠栭弻鍡楊吋閸℃瑯鏆撻梻浣告啞椤ㄥ棗煤濡 鏀﹂柍褜鍓熼弻锝呂旂€n偄顏�1.2.0 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂備礁鎲¢悷杈╃礊閳ь剚銇勯敐鍕祮闁瑰磭鍠栭弻鍡楊吋閸℃瑯鏆撻梻浣告啞椤ㄥ棗煤濡 鏀﹂柍褜鍓熼弻锝呂旂€n偄顏�1.2.0 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂佽绻愮换鎰崲閹扮増鍎嶆い鎺戝缁€鍐╃箾閹寸倖鎴犵矆鐎n喗鍊甸柣鐔煎亰濡插摜鈧娲樼划鎾诲箖瑜旈弫鎾绘晸閿燂拷2.7.4 闂備礁鎼崯鐗堢箾閳ь剚淇婇悙顒併仢闁哄苯鐭傞獮瀣攽閸偂绱欏┑鐑囩到濞村倿宕板Δ鍛瀬濠靛倸鎲¢崑瀣煥閻曞倹瀚�
闂佽绻愮换鎰崲閹扮増鍎嶆い鎺戝缁€鍐╃箾閹寸倖鎴犵矆鐎n喗鍊甸柣鐔煎亰濡插摜鈧娲樼划鎾诲箖瑜旈弫鎾绘晸閿燂拷2.7.4 闂備礁鎼崯鐗堢箾閳ь剚淇婇悙顒併仢闁哄苯鐭傞獮瀣攽閸偂绱欏┑鐑囩到濞村倿宕板Δ鍛瀬濠靛倸鎲¢崑瀣煥閻曞倹瀚� 闂備浇鐨崱鈺佹闂佸憡鐗楅〃鍫ュ箰瑜嶉埥澶娾堪閸曨厾娉�2闂備礁缍婂ḿ褔顢栭崱娑欏亯闁跨噦鎷�1.47.1 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂備浇鐨崱鈺佹闂佸憡鐗楅〃鍫ュ箰瑜嶉埥澶娾堪閸曨厾娉�2闂備礁缍婂ḿ褔顢栭崱娑欏亯闁跨噦鎷�1.47.1 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 濠电偞鍨堕幐鎾磻閹剧粯鍋g憸鏃堝绩閸楃偍缂氶柛顭戝亽濡插綊鏌i幇顖氱厫缂併劎濞€閹鎮烽柇锔叫﹂悗瑙勬礃缁捇骞冭瀹曟悂鏁撻敓锟�2.9.14 闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷
濠电偞鍨堕幐鎾磻閹剧粯鍋g憸鏃堝绩閸楃偍缂氶柛顭戝亽濡插綊鏌i幇顖氱厫缂併劎濞€閹鎮烽柇锔叫﹂悗瑙勬礃缁捇骞冭瀹曟悂鏁撻敓锟�2.9.14 闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷 闂佽崵濮烽崕銈夊垂閼测晝鐜婚柛銉墮绾偓闂佺偨鍎寸亸娆擃敂閺屻儱绾ч柣鎴濇喘濡绢喖顭胯缁挸顕i悽鍛婃優闁荤喖鍋婇弳顓㈡煟鎼淬値娼愰拑閬嶆煛瀹€鈧崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ絿纾�1.16.2 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂佽崵濮烽崕銈夊垂閼测晝鐜婚柛銉墮绾偓闂佺偨鍎寸亸娆擃敂閺屻儱绾ч柣鎴濇喘濡绢喖顭胯缁挸顕i悽鍛婃優闁荤喖鍋婇弳顓㈡煟鎼淬値娼愰拑閬嶆煛瀹€鈧崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ絿纾�1.16.2 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 闂備胶绮悷銉╁磹閸ф闂悷娆忓濡茶绻涢崱妯虹瑲缂侇煉鎷�8闂備礁鎼鍕濮樿泛鐒垫い鎺戝€搁弸搴ㄦ煕閿濆鏁辩紒鍌氱Ч楠炲饪伴崟顐紟闂備浇銆€閸嬫捇鏌涢敂璇插箹妞わ綇鎷�(闂備胶枪缁绘劗绮旈悽绋挎辈闁绘梻鍘х粻鍙夈亜閺冨倸甯堕柣锔兼嫹)v4.6.0j 闂傚倷绀佸鍫曞垂閻㈢數鍗氶柣銏⑶圭猾宥夋煟濡偐甯涙い搴㈢懇閺岋絽螖鐎n偄顏�
闂備胶绮悷銉╁磹閸ф闂悷娆忓濡茶绻涢崱妯虹瑲缂侇煉鎷�8闂備礁鎼鍕濮樿泛鐒垫い鎺戝€搁弸搴ㄦ煕閿濆鏁辩紒鍌氱Ч楠炲饪伴崟顐紟闂備浇銆€閸嬫捇鏌涢敂璇插箹妞わ綇鎷�(闂備胶枪缁绘劗绮旈悽绋挎辈闁绘梻鍘х粻鍙夈亜閺冨倸甯堕柣锔兼嫹)v4.6.0j 闂傚倷绀佸鍫曞垂閻㈢數鍗氶柣銏⑶圭猾宥夋煟濡偐甯涙い搴㈢懇閺岋絽螖鐎n偄顏� 闂備浇鐨崘銊х◤缂備胶濮抽崡鍐茬暦閿熺姴绀冩い蹇撳缁繝姊虹涵鍜佹綈婵炶尙鍠愮缓浠嬫晸閿燂拷2021闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷5.78 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂備浇鐨崘銊х◤缂備胶濮抽崡鍐茬暦閿熺姴绀冩い蹇撳缁繝姊虹涵鍜佹綈婵炶尙鍠愮缓浠嬫晸閿燂拷2021闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷5.78 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 婵犳鍠栭オ鐢电不閹寸偛绶為柣鏃傚帶缁€鍫ユ煙鏉堝墽鍒伴柣蹇ョ畵閺屻倝寮堕幐搴℃閻熸粍婢橀ˇ鐢哥嵁閳ь剙霉閿濆懏鎯堟い锝忔嫹1.0.1.2闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
婵犳鍠栭オ鐢电不閹寸偛绶為柣鏃傚帶缁€鍫ユ煙鏉堝墽鍒伴柣蹇ョ畵閺屻倝寮堕幐搴℃閻熸粍婢橀ˇ鐢哥嵁閳ь剙霉閿濆懏鎯堟い锝忔嫹1.0.1.2闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� 濠电偛顕慨鐢告偡閵夆斂鈧倿濡搁敃鈧閬嶆煟濡顒熼柛銈嗙o濠电姰鍨煎▔娑氱矓閹绢喖鐭楅悗鐢电《閸嬫捇鎮烽柇锔叫﹂悗瑙勬礃缁捇骞冭閺佹捇鏁撻敓锟�1.20.3闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷
濠电偛顕慨鐢告偡閵夆斂鈧倿濡搁敃鈧閬嶆煟濡顒熼柛銈嗙o濠电姰鍨煎▔娑氱矓閹绢喖鐭楅悗鐢电《閸嬫捇鎮烽柇锔叫﹂悗瑙勬礃缁捇骞冭閺佹捇鏁撻敓锟�1.20.3闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧☉椤ュ顭胯閹凤拷 婵犳鍠栭オ鐢电不閹寸偛绶為柣鏃傚劋鐎氭碍绻涢幋鐑嗘畼闁肩ǹ鐖奸弻鐔兼濞戝崬鍓遍梺缁樼墪閻栧ジ骞冭閺佹捇鏁撻敓锟�1.3.6 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷
婵犳鍠栭オ鐢电不閹寸偛绶為柣鏃傚劋鐎氭碍绻涢幋鐑嗘畼闁肩ǹ鐖奸弻鐔兼濞戝崬鍓遍梺缁樼墪閻栧ジ骞冭閺佹捇鏁撻敓锟�1.3.6 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾诲焵椤掑倹鍤€妞わ富鍨伴悾宄扳堪閸喎浜遍梺璺ㄥ櫐閹凤拷 闂備胶绮划宀勵敄閸儱鐒垫い鎺嗗亾闁硅櫕鎸搁悾鐑藉箮閼恒儱娈岄梺閫炲懏鍋�3.72.1.1 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗嗙€氬鏌嶈閸撶喎顕i鍕骇閻犳亽鍔嶅В澶愭⒑閸濆嫬鈧ǹ锕㈡潏銊︽珷闁跨噦鎷�
闂備胶绮划宀勵敄閸儱鐒垫い鎺嗗亾闁硅櫕鎸搁悾鐑藉箮閼恒儱娈岄梺閫炲懏鍋�3.72.1.1 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗嗙€氬鏌嶈閸撶喎顕i鍕骇閻犳亽鍔嶅В澶愭⒑閸濆嫬鈧ǹ锕㈡潏銊︽珷闁跨噦鎷� 闂佽崵濮撮鍕矆娓氣偓椤㈡瑥顓奸崶锔惧墾闂婎偄娲︾喊宥囪姳閻樼鍋撳▓鍨灓闁稿簺鍊栭弲璺衡堪閸繂鐝橀梺鎯х箳閹虫捇銆傜槐锟�1.0.49 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚�
闂佽崵濮撮鍕矆娓氣偓椤㈡瑥顓奸崶锔惧墾闂婎偄娲︾喊宥囪姳閻樼鍋撳▓鍨灓闁稿簺鍊栭弲璺衡堪閸繂鐝橀梺鎯х箳閹虫捇銆傜槐锟�1.0.49 闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鐗婇崑瀣煥閻曞倹瀚� mac缂備焦鍎宠ぐ鐐烘嚄鐠哄ソ楦跨疀濞戞ḿ顦梺绯曞墲椤ㄥ懘姊惧Ο灏栧亾鐟欏嫭鍋犻柛搴ㄤ憾瀹曪綁鏁撻敓锟�(Paragon Camptune X)V10.8.12闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
mac缂備焦鍎宠ぐ鐐烘嚄鐠哄ソ楦跨疀濞戞ḿ顦梺绯曞墲椤ㄥ懘姊惧Ο灏栧亾鐟欏嫭鍋犻柛搴ㄤ憾瀹曪綁鏁撻敓锟�(Paragon Camptune X)V10.8.12闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂備礁鍚嬪Σ鎺楋綖婢舵劖鍊跺鑸靛姇缁犺偐鈧箍鍎辩€氼喚绮欐繝鍕<妞ゆ牗绻傞崥鍦磼椤斿墽妲籄COSX 10.9.4 Mavericks闂佽娴烽幊鎾绘嚐椤栫偛鐭楅煫鍥ㄧ☉缁€鍌溾偓骞垮劚閻楀棝鎮楅銏$厽婵°倕顑嗙€氾拷
闂備礁鍚嬪Σ鎺楋綖婢舵劖鍊跺鑸靛姇缁犺偐鈧箍鍎辩€氼喚绮欐繝鍕<妞ゆ牗绻傞崥鍦磼椤斿墽妲籄COSX 10.9.4 Mavericks闂佽娴烽幊鎾绘嚐椤栫偛鐭楅煫鍥ㄧ☉缁€鍌溾偓骞垮劚閻楀棝鎮楅銏$厽婵°倕顑嗙€氾拷 Rar闂佽崵鍠愰悷杈╁緤閻e本鏆滈柛銉墮缁€鍡涙煃鏉炴壆鍔嶉柣婵愭ac闂備胶绮〃鍛熆閿燂拷1.4 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍х暦濡も偓椤撳ジ宕煎┑鍫氬亾椤撱垺鐓熸俊銈咁儐鐎氾拷
Rar闂佽崵鍠愰悷杈╁緤閻e本鏆滈柛銉墮缁€鍡涙煃鏉炴壆鍔嶉柣婵愭ac闂備胶绮〃鍛熆閿燂拷1.4 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍х暦濡も偓椤撳ジ宕煎┑鍫氬亾椤撱垺鐓熸俊銈咁儐鐎氾拷 Mac闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鍚橀悢鐓庣労闁告劑鍔庤ぐ鏌ユ⒑闂堚晝绉堕柟鍑ゆ嫹(ARC Welder)v1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
Mac闂佽娴烽幊鎾凰囬姘辨殾婵犲﹤鍚橀悢鐓庣労闁告劑鍔庤ぐ鏌ユ⒑闂堚晝绉堕柟鍑ゆ嫹(ARC Welder)v1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� Charles for MacV3.9.3闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
Charles for MacV3.9.3闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 闂備胶鎳撻崥瀣垝鎼达絺鍋撳顒傂㈤棁澶愮叓閸ャ劌鍤繛鍏兼閺屾盯鏁愰崒娑欘吙ac闂備胶绮〃鍛熆閿燂拷5.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
闂備胶鎳撻崥瀣垝鎼达絺鍋撳顒傂㈤棁澶愮叓閸ャ劌鍤繛鍏兼閺屾盯鏁愰崒娑欘吙ac闂備胶绮〃鍛熆閿燂拷5.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 闂傚倷鐒︾€笛囧礉閺嵮呮殼閹艰揪绲洪崑鎾荤嵁閸喚浠鹃梺绯曟櫆缁嬫挾鍒掗埡鍛剦闁荤儐鏌€闂備胶绮〃鍛耿閿燂拷1.33闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂傚倷鐒︾€笛囧礉閺嵮呮殼閹艰揪绲洪崑鎾荤嵁閸喚浠鹃梺绯曟櫆缁嬫挾鍒掗埡鍛剦闁荤儐鏌€闂備胶绮〃鍛耿閿燂拷1.33闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂傚⿴鍋勫ù鍌炲磻閸℃ɑ娅犻柣銏㈢c闂備胶绮〃鍛熆閿燂拷1.3.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
闂傚⿴鍋勫ù鍌炲磻閸℃ɑ娅犻柣銏㈢c闂備胶绮〃鍛熆閿燂拷1.3.2 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 闂備礁鎼鍕嚄閸洖纾婚柨婵嗘椤╂煡鏌¢崘銊モ偓濠氬箠婵夊穬c闂備胶绮〃鎰板箯閿燂拷7.13婵犳鍠楃换鎰緤閻e本顫曢柨鐔哄У閸嬪鏌ㄩ悤鍌涘
闂備礁鎼鍕嚄閸洖纾婚柨婵嗘椤╂煡鏌¢崘銊モ偓濠氬箠婵夊穬c闂備胶绮〃鎰板箯閿燂拷7.13婵犳鍠楃换鎰緤閻e本顫曢柨鐔哄У閸嬪鏌ㄩ悤鍌涘 Apple Logic Pro xV10.3.2
Apple Logic Pro xV10.3.2 Adobe Premiere Pro CC 2017 mac闂備胶绮〃鍛熆閿燂拷11.0.0 濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘
Adobe Premiere Pro CC 2017 mac闂備胶绮〃鍛熆閿燂拷11.0.0 濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘 闂備礁鎲¢〃鍛村疮椤愩垻鏆﹂柛顐犲劜椤ュ牊绻涢崱妤冪闁稿孩鎽c闂備胶绮〃鍛耿閿燂拷9.1.1 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂備礁鎲¢〃鍛村疮椤愩垻鏆﹂柛顐犲劜椤ュ牊绻涢崱妤冪闁稿孩鎽c闂備胶绮〃鍛耿閿燂拷9.1.1 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� Mac缂傚倸鍊搁崯顖炲垂閸︻厼鍨濋柛顐f礃閸庡酣鎮楀☉娅虫垹浜搁敓鐘茬骇闁绘垵妫楅悘鐔哥箾閸☆厽瀚�(MacTV)v0.121 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
Mac缂傚倸鍊搁崯顖炲垂閸︻厼鍨濋柛顐f礃閸庡酣鎮楀☉娅虫垹浜搁敓鐘茬骇闁绘垵妫楅悘鐔哥箾閸☆厽瀚�(MacTV)v0.121 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� Adobe Fireworks CS6 Mac闂備胶绮〃鍛耿閹憋拷6闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾跺垝婵犳艾鐒垫い鎺嶇劍婵挳鏌熼幑鎰敿闁告﹩鍓熼弻锟犲磼濮橆厼绐涙繝鈷€宥嗗
Adobe Fireworks CS6 Mac闂備胶绮〃鍛耿閹憋拷6闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎾跺垝婵犳艾鐒垫い鎺嶇劍婵挳鏌熼幑鎰敿闁告﹩鍓熼弻锟犲磼濮橆厼绐涙繝鈷€宥嗗 AutoCAD2015 mac濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌涢銈呮瀾闁归婀�1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
AutoCAD2015 mac濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌涢銈呮瀾闁归婀�1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� Adobe Photoshop cs6 mac闂備胶绮〃鍛熆閿燂拷13.0.3 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎰矙婢舵劦鏁囬柣鏂挎憸閳ь剦鍣i弻锝呂旂€n偄顏�
Adobe Photoshop cs6 mac闂備胶绮〃鍛熆閿燂拷13.0.3 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎰矙婢舵劦鏁囬柣鏂挎憸閳ь剦鍣i弻锝呂旂€n偄顏� Mac闂備焦妞块崢褰掑垂娴犲闂柧蹇撴贡绾惧吋淇婇婊冨妺缂佸倸鐗撳鍫曟倻閸℃浠у┑鐐叉4閹凤拷(Sketch mac)v3.3.2 濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘
Mac闂備焦妞块崢褰掑垂娴犲闂柧蹇撴贡绾惧吋淇婇婊冨妺缂佸倸鐗撳鍫曟倻閸℃浠у┑鐐叉4閹凤拷(Sketch mac)v3.3.2 濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘 Adobe After Effects cs6 mac闂備胶绮〃鍛熆閿燂拷1.0濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘
Adobe After Effects cs6 mac闂備胶绮〃鍛熆閿燂拷1.0濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘 Adobe InDesign cs6 mac1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎰矙婢舵劦鏁囬柣鏂挎憸閳ь剦鍣i弻锝呂旂€n偄顏�
Adobe InDesign cs6 mac1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鎰矙婢舵劦鏁囬柣鏂挎憸閳ь剦鍣i弻锝呂旂€n偄顏�![Mac闂備胶绮〃鍛存偋閸℃稑绠甸柍鍝勬噹缁犲鏌ㄩ悤鍌涘1.1.26 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘當婵犙傞儭mg]](https://p.e5n.com/up/2014-8/201484111558.jpg) Mac闂備胶绮〃鍛存偋閸℃稑绠甸柍鍝勬噹缁犲鏌ㄩ悤鍌涘1.1.26 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘當婵犙傞儭mg]
Mac闂備胶绮〃鍛存偋閸℃稑绠甸柍鍝勬噹缁犲鏌ㄩ悤鍌涘1.1.26 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘當婵犙傞儭mg] Mac闂佽崵濮村ú鈺咁敋瑜斿畷顖炲箵濡ょ稛S(Paragon NTFS for Mac)12.1.62 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
Mac闂佽崵濮村ú鈺咁敋瑜斿畷顖炲箵濡ょ稛S(Paragon NTFS for Mac)12.1.62 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 闂佸搫顦弲娑㈠箠濡ソ褰掓晸閿燂拷10 for macv3.4.1.4368 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂佸搫顦弲娑㈠箠濡ソ褰掓晸閿燂拷10 for macv3.4.1.4368 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� Mac濠电偞鍨堕幐鎼侇敄閸℃ぜ鈧帞鎹勬笟顖氭闂佸憡绻傜€氥劍绂嶉敐澶嬬厽闁靛ǹ鍎遍顐︽⒑椤旂⒈鍤熺紒杈ㄥ浮閹垽宕妷顔荤穿闂備浇宕甸崑娑樜涘Δ浣割嚤闁圭増婢樼粈鍌炴煥閻曞倹瀚�(CleanMyMac for mac)v3.1.1 婵犳鍠楃换鎰緤閻e本顫曢柨鐔哄У閸嬪鏌ㄩ悤鍌涘
Mac濠电偞鍨堕幐鎼侇敄閸℃ぜ鈧帞鎹勬笟顖氭闂佸憡绻傜€氥劍绂嶉敐澶嬬厽闁靛ǹ鍎遍顐︽⒑椤旂⒈鍤熺紒杈ㄥ浮閹垽宕妷顔荤穿闂備浇宕甸崑娑樜涘Δ浣割嚤闁圭増婢樼粈鍌炴煥閻曞倹瀚�(CleanMyMac for mac)v3.1.1 婵犳鍠楃换鎰緤閻e本顫曢柨鐔哄У閸嬪鏌ㄩ悤鍌涘 闂備礁鍚嬪Σ鎺楋綖婢舵劖鍊跺┑澶嗗亾ootCamp5.1.5640 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂備礁鍚嬪Σ鎺楋綖婢舵劖鍊跺┑澶嗗亾ootCamp5.1.5640 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闁诲海鏁婚崑濠囧窗閺囩喓鈹嶅┑鍌滄枾ad闂備胶绮〃鎰板箯閿燂拷2020v7.0.12 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闁诲海鏁婚崑濠囧窗閺囩喓鈹嶅┑鍌滄枾ad闂備胶绮〃鎰板箯閿燂拷2020v7.0.12 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 iphone闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞呮儶q2021v8.5.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
iphone闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞呮儶q2021v8.5.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 闂備礁鎼€氼參骞愰柨瀣攳濠靛倻绗係闂備胶绮〃鍛熆閿燂拷7.3.13 iPhone闂備胶绮〃鎰板箯閿燂拷
闂備礁鎼€氼參骞愰柨瀣攳濠靛倻绗係闂備胶绮〃鍛熆閿燂拷7.3.13 iPhone闂備胶绮〃鎰板箯閿燂拷 闂傚倸鍊哥€氼剟鎯岄崒姘肩€堕柨鐕傛嫹 iphoneV8.32.4 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷�
闂傚倸鍊哥€氼剟鎯岄崒姘肩€堕柨鐕傛嫹 iphoneV8.32.4 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰搴綖閵忋倖鏅查柛娑卞灣椤㈠懘姊虹紒姗嗘闁瑰嚖鎷� 闂備礁鎲¢〃鍛村疮閻楀牊娅犻柨鐕傛嫹 iphone闂備胶绮〃鎰板箯閿燂拷9.2.5 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闂備礁鎲¢〃鍛村疮閻楀牊娅犻柨鐕傛嫹 iphone闂備胶绮〃鎰板箯閿燂拷9.2.5 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 99濠电偞鍨堕幐鍫曞磿閻㈢ǹ鐒垫い鎺嗗亾妞わ附婢橀妴鎺楀醇閺囩偞顥濋梺瑙勵問閸犳牠銆傜化锟�1.3.6
99濠电偞鍨堕幐鍫曞磿閻㈢ǹ鐒垫い鎺嗗亾妞わ附婢橀妴鎺楀醇閺囩偞顥濋梺瑙勵問閸犳牠銆傜化锟�1.3.6 闂傚⿴鍋勫ù鍌炲磻閸℃ɑ娅犻柣銏⑽攈one闂備胶绮〃鎰板箯閿燂拷5.7.3 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闂傚⿴鍋勫ù鍌炲磻閸℃ɑ娅犻柣銏⑽攈one闂備胶绮〃鎰板箯閿燂拷5.7.3 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 婵犵數鍎戠徊楣冩晪闂佹眹鍊ч幏锟� for iPhonev9.5.15 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
婵犵數鍎戠徊楣冩晪闂佹眹鍊ч幏锟� for iPhonev9.5.15 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 濠电姭鎷冩担绋款潊闂佺鍩栭〃鍡楊嚗閸曨垰鐓涢柛灞剧矋閻︼拷 for iphoneV7.5.3闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ絿纭癙A
濠电姭鎷冩担绋款潊闂佺鍩栭〃鍡楊嚗閸曨垰鐓涢柛灞剧矋閻︼拷 for iphoneV7.5.3闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ絿纭癙A 闂佽崵濮撮澶愬绩闁秵鍋ら柡鍥ュ灩閹瑰爼鏌℃径瀣嚋缂佸倸娼焢hone(Google Maps)4.54 濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘
闂佽崵濮撮澶愬绩闁秵鍋ら柡鍥ュ灩閹瑰爼鏌℃径瀣嚋缂佸倸娼焢hone(Google Maps)4.54 濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘![闂傚⿴鍋勫ù鍌炲磻閸涙潙绠伴梺顒€绉甸崵鎰版偡濞嗗繐顏ù婊庡灦閺岋絽螖閳ь剙锕㈤敓锟�3.3.35 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜斿畷椋庡寲缁涚禈]](https://p.e5n.com/up/2011-12/20111215155620.gif) 闂傚⿴鍋勫ù鍌炲磻閸涙潙绠伴梺顒€绉甸崵鎰版偡濞嗗繐顏ù婊庡灦閺岋絽螖閳ь剙锕㈤敓锟�3.3.35 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜斿畷椋庡寲缁涚禈]
闂傚⿴鍋勫ù鍌炲磻閸涙潙绠伴梺顒€绉甸崵鎰版偡濞嗗繐顏ù婊庡灦閺岋絽螖閳ь剙锕㈤敓锟�3.3.35 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜斿畷椋庡寲缁涚禈] 闂備礁鎲¢懝楣兯囬鐐茬畺闊洦鍝庢禍褰掓⒑椤掆偓缁夊爼宕fィ鍐╃厵缂備降鍨归獮妤呮煛閸屾瑧绐旂€规洘濞婇崺锟犅ㄧ粊宥夋⒑缂佹﹩娈i柟鍑ゆ嫹1.0.1017 闂備礁鍚嬪Σ鎺楋綖婢舵劖鍊跺┑澶屾箲ad闂備胶绮〃鎰板箯閿燂拷
闂備礁鎲¢懝楣兯囬鐐茬畺闊洦鍝庢禍褰掓⒑椤掆偓缁夊爼宕fィ鍐╃厵缂備降鍨归獮妤呮煛閸屾瑧绐旂€规洘濞婇崺锟犅ㄧ粊宥夋⒑缂佹﹩娈i柟鍑ゆ嫹1.0.1017 闂備礁鍚嬪Σ鎺楋綖婢舵劖鍊跺┑澶屾箲ad闂備胶绮〃鎰板箯閿燂拷 闁荤喐绮堥崡铏閸洘鍋傞柛顐f礀缁€鍌炴煕椤愮姴鍔滈柡渚€浜堕弻鐔虹磼閵忕姴绠洪梺鍝勫€风欢姘暦閹惰棄鐓涙い褏顨掗梻浣虹帛椤ㄦ劙骞忛敓锟�2.8.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闁荤喐绮堥崡铏閸洘鍋傞柛顐f礀缁€鍌炴煕椤愮姴鍔滈柡渚€浜堕弻鐔虹磼閵忕姴绠洪梺鍝勫€风欢姘暦閹惰棄鐓涙い褏顨掗梻浣虹帛椤ㄦ劙骞忛敓锟�2.8.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 闂備礁鎼崐褰掋€冩繝鍐檮闁哄啫鐗婇崕搴ㄦ倵濞戞鎴犱焊閿熺姵鍊垫鐐茬仢閻忣亪鏌涢埡鍌溿€掔紒顔规櫊閹偓闁绘牕鐛遍梻浣虹帛椤ㄦ劙骞忛敓锟�7.0.1 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂備礁鎼崐褰掋€冩繝鍐檮闁哄啫鐗婇崕搴ㄦ倵濞戞鎴犱焊閿熺姵鍊垫鐐茬仢閻忣亪鏌涢埡鍌溿€掔紒顔规櫊閹偓闁绘牕鐛遍梻浣虹帛椤ㄦ劙骞忛敓锟�7.0.1 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂傚倷妞掗崡鎶剿夐幘鍨涘亾濮橆剛效婵☆偄鎳樺畷妤呭川椤栵絽鏁� for iPhonev10.9.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂傚倷妞掗崡鎶剿夐幘鍨涘亾濮橆剛效婵☆偄鎳樺畷妤呭川椤栵絽鏁� for iPhonev10.9.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� How old do I look ios闂備胶绮〃鎰板箯閿燂拷1.02 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
How old do I look ios闂備胶绮〃鎰板箯閿燂拷1.02 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 缂傚倸鍊稿ú銈嗩殽缁嬫5鐟拔熼懖鈺冪厠闂侀€炲苯澧扮紒顔芥閸┾偓闁荤偟婢媓one闂備胶绮〃鍛耿閿燂拷8.6.62 闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧矊椤e吋銇勯幒鎾剁煀妞ゆ洩缍€缁犳盯寮撮悜鍡樻瘔
缂傚倸鍊稿ú銈嗩殽缁嬫5鐟拔熼懖鈺冪厠闂侀€炲苯澧扮紒顔芥閸┾偓闁荤偟婢媓one闂備胶绮〃鍛耿閿燂拷8.6.62 闂備礁鎼悧鍐磻閹剧粯鐓涢柛灞剧矊椤e吋銇勯幒鎾剁煀妞ゆ洩缍€缁犳盯寮撮悜鍡樻瘔 婵犳鍠楄摫婵炲吋鐟ラ悾鐢稿礃椤旇В鎸€闂佺粯鏌ㄩ崥瀣掗幇鐗堢厾闁哄嫬娴氬ḿ鎰版煟韫囨搩妯€闁诡啫鍥ч敜闁跨噦鎷�1.0.0
婵犳鍠楄摫婵炲吋鐟ラ悾鐢稿礃椤旇В鎸€闂佺粯鏌ㄩ崥瀣掗幇鐗堢厾闁哄嫬娴氬ḿ鎰版煟韫囨搩妯€闁诡啫鍥ч敜闁跨噦鎷�1.0.0 濠电姰鍨归悘鍫ュ疾濞戙垹桅濠靛鎮傞弻娑㈠Ψ瑜忛埞濉竌d闂備胶绮〃鎰板箯閿燂拷5.7.4 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
濠电姰鍨归悘鍫ュ疾濞戙垹桅濠靛鎮傞弻娑㈠Ψ瑜忛埞濉竌d闂備胶绮〃鎰板箯閿燂拷5.7.4 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 闂傚⿴鍋勫ù鍌炲磻閸涱喗娅犳繛鎾崇崻s闂備胶绮〃鍛耿閿燂拷9.6.30 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
闂傚⿴鍋勫ù鍌炲磻閸涱喗娅犳繛鎾崇崻s闂備胶绮〃鍛耿閿燂拷9.6.30 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷 闂備胶鍘ч崯鍧楁嚐椤栨壕鍋撻崹顐€跨€规洜鍏樺鍫曞箰鎼达綆娲痠os闂備胶绮〃鎰板箯閿燂拷1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂備胶鍘ч崯鍧楁嚐椤栨壕鍋撻崹顐€跨€规洜鍏樺鍫曞箰鎼达綆娲痠os闂備胶绮〃鎰板箯閿燂拷1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� 闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞屽墴閹鎮烽柇锔叫﹂梺鍛婄懃缁绘ê鐣峰┑瀣厸闁稿本鍑归弶褰掓⒑閸忓吋顫楁い顐㈩樀閹ɑ寰勯幇顓炰罕闂佺宥嗗1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷�
闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞屽墴閹鎮烽柇锔叫﹂梺鍛婄懃缁绘ê鐣峰┑瀣厸闁稿本鍑归弶褰掓⒑閸忓吋顫楁い顐㈩樀閹ɑ寰勯幇顓炰罕闂佺宥嗗1.0 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍ь嚕閻㈢ǹ鐒垫い鎺戝濡﹢鏌熷▓鍨灈妞わ綇鎷� UC婵犵數鍋炲ḿ娆戞崲濡ゅ拑缍栫€广儱顦梻顖炴煃閻氬瓨瀚�113.5.5.1555濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘
UC婵犵數鍋炲ḿ娆戞崲濡ゅ拑缍栫€广儱顦梻顖炴煃閻氬瓨瀚�113.5.5.1555濠电偞鍨堕幖鈺呭储娴犲鍑犻柛鎰靛枟閸嬪鏌ㄩ悤鍌涘 360婵犵數鍋炲ḿ娆戞崲濡ゅ拑缍栫€广儱顦梻顖炴煃閳轰緡鏀� for iPadV4.1.3 婵犳鍠楃换鎰緤閻e本顫曢柨鐔哄У閸嬪鏌ㄩ悤鍌涘
360婵犵數鍋炲ḿ娆戞崲濡ゅ拑缍栫€广儱顦梻顖炴煃閳轰緡鏀� for iPadV4.1.3 婵犳鍠楃换鎰緤閻e本顫曢柨鐔哄У閸嬪鏌ㄩ悤鍌涘 iPhone闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞呮倵Q婵犵數鍋炲ḿ娆戞崲濡ゅ拑缍栫€广儱顦梻顖炴煃閻氬瓨瀚�8.9.1 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
iPhone闂備礁缍婂ḿ褔顢栭崱妞绘敠闁逞呮倵Q婵犵數鍋炲ḿ娆戞崲濡ゅ拑缍栫€广儱顦梻顖炴煃閻氬瓨瀚�8.9.1 闂佽姘﹂~澶庢懌闂佸搫鐬奸崰鏍箖瑜旈弫鎾绘晸閿燂拷
Lucene总的来说是:
- 一个高效的,可扩展的,全文检索库。
- 全部用Java实现,无须配置。
- 仅支持纯文本文件的索引(Indexing)和搜索(Search)。
- 不负责由其他格式的文件抽取纯文本文件,或从网络中抓取文件的过程。
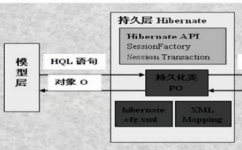
在Lucene in action中,Lucene 的构架和过程如下图,

说明Lucene是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。
让我们更细一些看Lucene的各组件:

- 被索引的文档用Document对象表示。
- IndexWriter通过函数addDocument将文档添加到索引中,实现创建索引的过程。
- Lucene的索引是应用反向索引。
- 当用户有请求时,Query代表用户的查询语句。
- IndexSearcher通过函数search搜索Lucene Index。
- IndexSearcher计算term weight和score并且将结果返回给用户。
- 返回给用户的文档集合用TopDocsCollector表示。
那么如何应用这些组件呢?
让我们再详细到对Lucene API 的调用实现索引和搜索过程。

- 索引过程如下:
- 创建一个IndexWriter用来写索引文件,它有几个参数,INDEX_DIR就是索引文件所存放的位置,Analyzer便是用来对文档进行词法分析和语言处理的。
- 创建一个Document代表我们要索引的文档。
- 将不同的Field加入到文档中。我们知道,一篇文档有多种信息,如题目,作者,修改时间,内容等。不同类型的信息用不同的Field来表示,在本例子中,一共有两类信息进行了索引,一个是文件路径,一个是文件内容。其中FileReader的SRC_FILE就表示要索引的源文件。
- IndexWriter调用函数addDocument将索引写到索引文件夹中。
- 搜索过程如下:
- IndexReader将磁盘上的索引信息读入到内存,INDEX_DIR就是索引文件存放的位置。
- 创建IndexSearcher准备进行搜索。
- 创建Analyer用来对查询语句进行词法分析和语言处理。
- 创建QueryParser用来对查询语句进行语法分析。
- QueryParser调用parser进行语法分析,形成查询语法树,放到Query中。
- IndexSearcher调用search对查询语法树Query进行搜索,得到结果TopScoreDocCollector。
以上便是Lucene API函数的简单调用。
然而当进入Lucene的源代码后,发现Lucene有很多包,关系错综复杂。
然而通过下图,我们不难发现,Lucene的各源码模块,都是对普通索引和搜索过程的一种实现。
此图是上一节介绍的全文检索的流程对应的Lucene实现的包结构。(参照http://www.lucene.com.cn/about.htm中文章《开放源代码的全文检索引擎Lucene》)

- Lucene的analysis模块主要负责词法分析及语言处理而形成Term。
- Lucene的index模块主要负责索引的创建,里面有IndexWriter。
- Lucene的store模块主要负责索引的读写。
- Lucene的QueryParser主要负责语法分析。
- Lucene的search模块主要负责对索引的搜索。
- Lucene的similarity模块主要负责对相关性打分的实现。
了解了Lucene的整个结构,我们便可以开始Lucene的源码之旅了。
 喜欢
喜欢  顶
顶 难过
难过 囧
囧 围观
围观 无聊
无聊