
�ڼ������û�г���֮ǰ����һ�ֽ����紫���ֻ���Teletype Model 33�������⣬ÿ���ӿ��Դ�10���ַ�����������һ�����⣬���Ǵ���һ�л��е�ʱ��Ҫ��ȥ0.2�룬���ÿ��Դ������ַ���Ҫ������0.2�����棬�����µ��ַ�����������ô����ַ�����ʧ��
���ǣ�������Ա���˸��취���������⣬������ÿ�к����������ʾ�������ַ���һ������"�س�"�����ߴ��ֻ��Ѵ�ӡͷ��λ����߽磻��һ������"����"�����ߴ��ֻ���ֽ������һ�С�
�����"����"��"�س�"�������������ǵ�Ӣ��������Ҳ���Կ���һ����
����������������ˣ�����������Ҳ�ͱ��㵽�˼�����ϡ���ʱ���洢���ܹ�һЩ��ѧ����Ϊ��ÿ�н�β�������ַ�̫�˷��ˣ���һ���Ϳ��ԡ����ǣ��ͳ����˷��硣
Unixϵͳ�ÿ�н�βֻ��"<����>"����"\n"��Windowsϵͳ������ÿ�н�β��"<�س�><����>"����"\r\n"��Macϵͳ�ÿ�н�β��"<�س�>"��һ��ֱ�Ӻ���ǣ�Unix/Macϵͳ�µ��ļ���Windows��Ļ����������ֻ���һ�У���Windows����ļ���Unix/Mac�´Ļ�����ÿ�еĽ�β���ܻ���һ��^M���š�
�����linux�´������ı��ļ���windows�л�����һ�У���Ϊwindows��Ϊû�л��з���CRLF����
��windows�´������ı��ļ���linux�����������ÿһ�к������һ��^M�����^MҪ��ctrl + v ctrl + m�������������˼����CR(Carriage Return).
˵����������Ҳ�����ʣ�Ϊʲô����windows�´������ı��ļ�����linux����ʾ�����أ�
���磬����windows�´���һ���ı��ļ�a.txt���ŵ��ҵ�linux�У���vim��
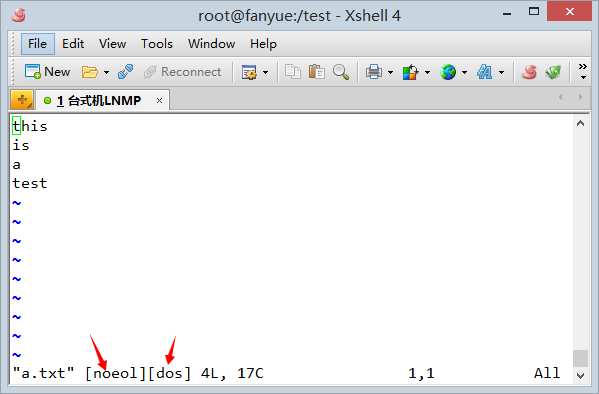
���Կ�����ʾ����������еĽ�β��û��^M���š�������Ϊvim�ڴ��ļ�ʱ�����Զ����з�������ı������л��з�����^M$(CRLF, ��windows�Ļ��б��)����ôvim���Զ���dos��ʽ��ʾ�ı����ݣ����Ե�ÿһ�н�β��^M$������ı���ʾ�������ġ�
ע��������ͼƬ��������ͷָʾ��vim�༭�����·���������־[noeol]��[dos]���������͵ڶ�����־"[dos]"�����ʾvimʶ���ı���ÿһ�ж���^M$�Ļ��з������vim�Զ���dos�ı���ʽ����ʾ�ļ����������ǿ����ı���ʾ�������ġ�
��ôΪʲô�е�ʱ��windows�´�����༭���ļ���linux�»����^M�أ�vim�������Զ�ʶ����������Ϊ��vim�����ı���ÿһ�л��з���ֻҪ��һ�еĻ��з�����windows��ʽ����ôvim�ͻ���unix�ļ���ʽ����ʾ�ļ�����ʱ���з�Ϊ$, ������ǻῴ���ı����к������һ��^M���š�
��������cat -A��ʾ�ļ���������ţ�

�ļ�һ�����У����Կ����з�����^M$����ͷ��ָ�������vim����[dos]�ļ���ʽ����ʾ����ı���
���ﻹ���Է����ļ������һ��û�л��з�������ǵ�һ��ͼvim�е�[noeol]��־������ ����Ϊ��windows�´������ı������һ���Dz�����ϻ��з��ģ���linux�´������ı��Ĺ�����ÿһ�ж��л��з����������һ�С����vim����ʾno end-of-line, ������������ļ�����û�л��з��������С�
��wc -lͳ������ļ���������
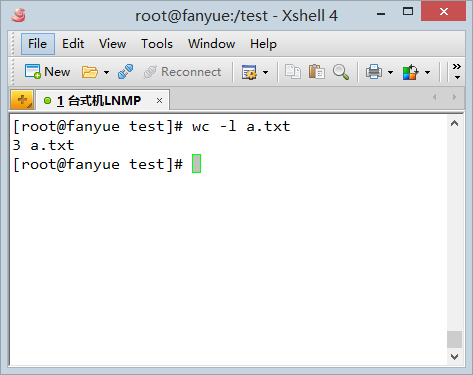
�����3�У�����һ�У�ԭ�����ļ������һ��û�л��з���
����linux����vim�༭һ�����ļ������ݺոյ�a.txtһ������cat -A�鿴��
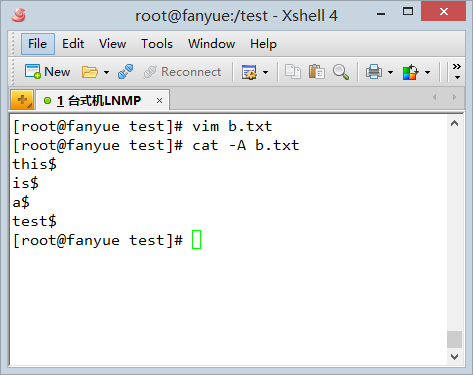
���Կ���linux�´������ı���ÿһ�ж����л��з��ģ��������һ�У���wc -lͳ��������

��ʱͳ�ƽ����ȷ��
����sed�滻windows�´�����a.txt, ������һ�еĻ��з�^M$�е�^Mȥ�������linux�Ļ��з�$
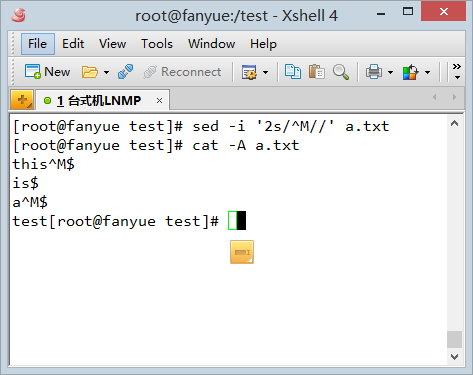
�����Ұ��ļ��ĵڶ��еĻ��з��滻����linux��ʽ��$��ע��sed�����е�^M
���������в���ֱ�����룬���� ctrl+v��ctrl+m. ����vim������ļ���

���ڵڶ��еĻ��з�����^M$��ʽ��vim������dos�ļ���ʽ����ʾ�ļ��������Է���vim�·�û��[dos]����ʾ�ˣ�����vim��unix�ļ���ʽ����ʾ����ļ������һЩ�еĺ�������һ��^M��־��
���䣺sed��windows���з��Ĵ���
ͨ���������֪��vim����һ��ȫ��ʹ��windows��ʽ���з����ı��ļ�����[dos]ģʽ����ʾ����ı����Զ�������β��^M.
������ʹ��sed�����һЩ�ļ�ʱ�������һ��������ʾ�������ļ�����sed����֮���ٴ��ļ�ʱ�����ٴγ��������^M. ��ôsed����δ���windows���з����ı��أ�
����windows�´���һ���ı��ļ��������ҵ�linux�С���cat -A ��ʾ�����ַ���

��������һ��û�л��з��������еĻ��з�Ϊ^M$, ʹ��sed��������ı��ļ�����ڶ�������һЩ���ݣ�����cat -A�鿴��
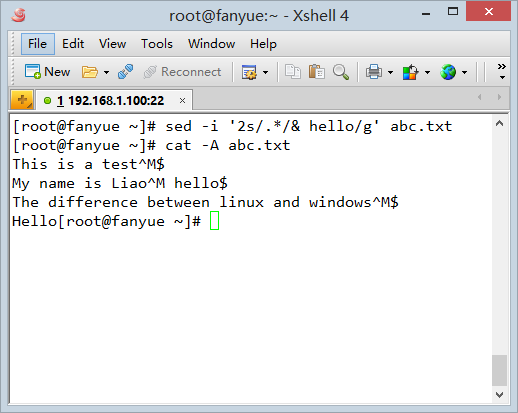
��������.*ƥ��ڶ��е��������ݣ�&��ʾƥ�䵽���������ݣ���&�����Ҽ�����һЩ���ݣ���cat -A�鿴���֣�sed�ڴ����滻ʱ�����ƥ�䵽�����У���ôƥ��������dz��˻��з�$(Linux ���з�)����������ݣ���ʹ����ı��Ļ��з���^M$(windows ���з�).
��˵ڶ��е��ı���sed������^M���ҵ��������ʽ.*�����ı����ݶ�ƥ�䵽�ˣ���$���ᱻƥ�䣬��Զ���е�ĩβ�䵱���з�������һ��^M��$�ͱ���ɢ�ˡ������һ�еĻ��з��ڴ������Ϊ��linux��ʽ�Ļ��з�$. ��vim��Ч�����£�
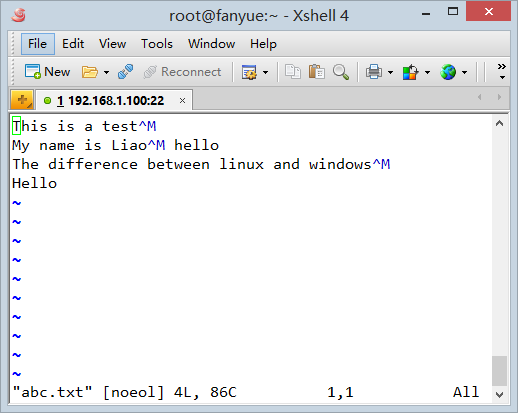
��Ϊ�ļ��Ļ��з���linux��windows���ӵģ�vim��unix�ļ���ʽ��ʾ����ļ����ļ���^M����ʾ���������ҵڶ��е�^M��sedƥ�䵽�����������β��vim�·���[noeol]ԭ�������һ����windows��û�л��з������Ҳû��^M.
�ó����ۣ�sed����ļ��е�^M�����ļ���������������������sed����windows�´������ı��ļ������п����ڴ���֮����ʾʱ���������^M. �����������ı���������δ���windows�Ļ��з������д���һ���о���
����
windows�´������ļ����з�Ϊ^M$�������һ�н�βû�л��з�
linux�´������ļ���ÿһ�ж����Ի��з�$�������������һ��
vim���ļ�ʱ������ļ������л��з�����dos��ʽ��^M$����ôvim���Զ���dos�ļ���ʽ����ʾ�ı��ļ����������Ĭ�ϵ�unix��ʽ��ʾ�ı������ǿ��ܻ����еĽ�β����^M�ķ���
wc -l����$���з���ͳ�������ģ����windows�´������ļ�ʹ��wc -lͳ������ʱ����һ��
һ��windows�´������ļ�����linux����ʾ������������ijЩ�ı����������sed�������ļ���ijЩ���з����ܻ�ı䣬�����ʾ������
sed�����ļ�ʱ�����windows���з��е�^M�����ļ����ݣ���sedֻ����$��Ϊ��ĩβ�Ļ��з�����˿��ܻ���ɻ��з���һ�¡�
 ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����



