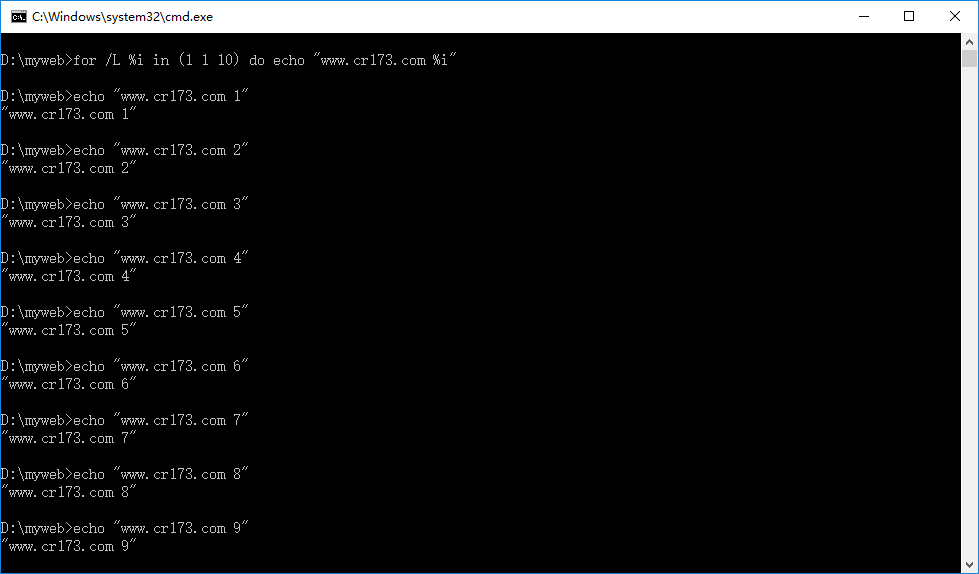
ЛљгкШЮКЮЦНЬЈЪЕЯжЕФдЦХЬЯЕЭГЃЌУцСйЕФЪзвЊЕФММЪѕЮЪЬтОЭЪЧПЭЛЇЖЫЩЯДЋКЭЯТдиаЇТЪгХЛЏЮЪЬтЁЃЛљгкHadoopЪЕЯжЕФдЦХЬЯЕЭГЃЌЪмЕНHadoopЮФМўЖСаДЛњжЦЕФгАЯьЃЌВЩгУHadoopЬсЙЉЕФAPIНјааHDFSЮФМўЯЕЭГЗУЮЪЃЌЮФМўЖСШЁЪБФЌШЯЪЧЫГађЁЂж№blockЖСШЁЃЛаДШыЪБЪЧЫГађаДШыЁЃ
вЛЁЂЖСаДЛњжЦЁЁЁЁ
ЪзЯШРДПДЮФМўЖСШЁЛњжЦЃКОЁЙмDataNodeЪЕЯжСЫЮФМўДцДЂПеМфЕФЫЎЦНРЉеЙКЭЖрИББОЛњжЦЃЌЕЋЪЧеыЖдЕЅИіОпЬхЮФМўЕФЖСШЁЃЌHadoopФЌШЯЕФAPIНгПкВЂУЛгаЬсЙЉЖрDataNodeЕФВЂааЖСШЁЛњжЦЁЃЛљгкHadoopЬсЙЉЕФAPIНгПкЪЕЯжЕФдЦХЬПЭЛЇЖЫвВздШЛУцСйЭЌбљЕФЮЪЬтЁЃHadoopЕФЮФМўЖСШЁСїГЬШчЯТЭМЫљЪОЃК

ЪЙгУHDFSЬсЙЉЕФПЭЛЇЖЫПЊЗЂПтЃЌЯђдЖГЬЕФNamenodeЗЂЦ№RPCЧыЧѓЃЛ
NamenodeЛсЪгЧщПіЗЕЛиЮФМўЕФВПЗжЛђепШЋВПblockСаБэЃЌЖдгкУПИіblockЃЌNamenodeЖМЛсЗЕЛигаИУblockПНБДЕФdatanodeЕижЗЃЛ
ПЭЛЇЖЫПЊЗЂПтЛсбЁШЁРыПЭЛЇЖЫзюНгНќЕФdatanodeРДЖСШЁblockЃЛ
ЖСШЁЭъЕБЧАblockЕФЪ§ОнКѓЃЌЙиБегыЕБЧАЕФdatanodeСЌНгЃЌВЂЮЊЖСШЁЯТвЛИіblockбАевзюМбЕФdatanodeЃЛ
ЕБЖСЭъСаБэЕФblockКѓЃЌЧвЮФМўЖСШЁЛЙУЛгаНсЪјЃЌПЭЛЇЖЫПЊЗЂПтЛсМЬајЯђNamenodeЛёШЁЯТвЛХњЕФblockСаБэЁЃ
ЖСШЁЭъвЛИіblockЖМЛсНјааchecksumбщжЄЃЌШчЙћЖСШЁdatanodeЪБГіЯжДэЮѓЃЌПЭЛЇЖЫЛсЭЈжЊNamenodeЃЌШЛКѓдйДгЯТвЛИігЕгаИУblockПНБДЕФdatanodeМЬајЖСШЁЁЃ
етРяашвЊзЂвтЕФЙиМќЕуЪЧЃКЖрИіDatanodeЫГађЖСШЁЁЃ
ЦфДЮдйПДЮФМўЕФаДШыЛњжЦЃК
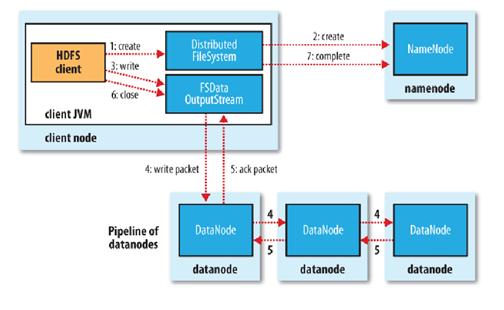
ЪЙгУHDFSЬсЙЉЕФПЭЛЇЖЫПЊЗЂПтЃЌЯђдЖГЬЕФNamenodeЗЂЦ№RPCЧыЧѓЃЛ
NamenodeЛсМьВщвЊДДНЈЕФЮФМўЪЧЗёвбОДцдкЃЌДДНЈепЪЧЗёгаШЈЯоНјааВйзїЃЌГЩЙІдђЛсЮЊЮФМўДДНЈвЛИіМЧТМЃЌЗёдђЛсШУПЭЛЇЖЫХзГівьГЃЃЛ
ЕБПЭЛЇЖЫПЊЪМаДШыЮФМўЕФЪБКђЃЌПЊЗЂПтЛсНЋЮФМўЧаЗжГЩЖрИіpacketsЃЌВЂдкФкВПвд"data queue"ЕФаЮЪНЙмРэетаЉpacketsЃЌВЂЯђNamenodeЩъЧыаТЕФblocksЃЌЛёШЁгУРДДцДЂreplicasЕФКЯЪЪЕФdatanodesСаБэЃЌ СаБэЕФДѓаЁИљОндкNamenodeжаЖдreplicationЕФЩшжУЖјЖЈЁЃПЊЪМвдpipelineЃЈЙмЕРЃЉЕФаЮЪННЋpacketаДШыЫљгаЕФreplicasжаЁЃПЊЗЂПтАбpacketвдСїЕФЗНЪНаДШыЕквЛИі datanodeЃЌИУdatanodeАбИУpacketДцДЂжЎКѓЃЌдйНЋЦфДЋЕнИјдкДЫpipelineжаЕФЯТвЛИіdatanodeЃЌжБЕНзюКѓвЛИі datanodeЃЌетжжаДЪ§ОнЕФЗНЪНГЪСїЫЎЯпЕФаЮЪНЁЃ
зюКѓвЛИіdatanodeГЩЙІДцДЂжЎКѓЛсЗЕЛивЛИіack packetЃЌдкpipelineРяДЋЕнжСПЭЛЇЖЫЃЌдкПЭЛЇЖЫЕФПЊЗЂПтФкВПЮЌЛЄзХ"ack queue"ЃЌГЩЙІЪеЕНdatanodeЗЕЛиЕФack packetКѓЛсДг"ack queue"вЦГ§ЯргІЕФpacketЁЃ
ШчЙћДЋЪфЙ§ГЬжаЃЌгаФГИіdatanodeГіЯжСЫЙЪеЯЃЌФЧУДЕБЧАЕФpipelineЛсБЛЙиБеЃЌГіЯжЙЪеЯЕФdatanodeЛсДгЕБЧАЕФ pipelineжавЦГ§ЃЌЪЃгрЕФblockЛсМЬајЪЃЯТЕФdatanodeжаМЬајвдpipelineЕФаЮЪНДЋЪфЃЌЭЌЪБNamenodeЛсЗжХфвЛИіаТЕФ datanodeЃЌБЃГжreplicasЩшЖЈЕФЪ§СПЁЃ
ЙиМќДЪЃКПЊЗЂПтАбpacketвдСїЕФЗНЪНаДШыЕквЛИіdatanodeЃЌИУdatanodeНЋЦфДЋЕнИјpipelineжаЕФЯТвЛИіdatanodeЃЌжЊЕРзюКѓвЛИіDatanodeЃЌетжжаДЪ§ОнЕФЗНЪНГЪСїЫЎЯпЗНЪНЁЃ
ЖўЁЂНтОіЗНАИ
1.ЯТдиаЇТЪгХЛЏ
ЭЈЙ§вдЩЯЖСаДЛњжЦЕФЗжЮіЃЌЮвУЧПЩвдЗЂЯжЛљгкHadoopЪЕЯжЕФдЦХЬПЭЛЇЖЮЯТдиаЇТЪЕФгХЛЏПЩвдДгСНИіВуМЖзХЪжЃК
1.ЮФМўећЬхВуУцЃКВЩгУВЂааЗУЮЪЖрЯпГЬЃЈЖрНјГЬЃЉЗнЖрЮФМўВЂааЖСШЁЁЃ
2.BlockПщЖСШЁЃКИФаДHadoopНгПкРЉеЙЃЌЖрBlockВЂааЖСШЁЁЃ
2.ЩЯДЋаЇТЪгХЛЏ
ЩЯДЋаЇТЪгХЛЏжЛФмВЩгУЮФМўећЬхВуУцЕФВЂааДІРэЃЌВЛжЇГжЗжBlockЛњжЦЕФЖрBlockВЂааЖСШЁЁЃ
HDFSДІРэДѓСПаЁЮФМўЪБЕФЮЪЬт
аЁЮФМўжИЕФЪЧФЧаЉsizeБШHDFS ЕФblock size(ФЌШЯ64M)аЁЕФЖрЕФЮФМўЁЃШчЙћдкHDFSжаДцДЂаЁЮФМўЃЌФЧУДдкHDFSжаПЯЖЈЛсКЌгааэаэЖрЖретбљЕФаЁЮФМў(ВЛШЛОЭВЛЛсгУhadoopСЫ)ЁЃ
ЖјHDFSЕФЮЪЬтдкгкЮоЗЈКмгааЇЕФДІРэДѓСПаЁЮФМўЁЃ
ШЮКЮвЛИіЮФМўЃЌФПТМКЭblockЃЌдкHDFSжаЖМЛсБЛБэЪОЮЊвЛИіobjectДцДЂдкnamenodeЕФФкДцжаЃЌУЛвЛИіobjectеМгУ150 bytesЕФФкДцПеМфЁЃЫљвдЃЌШчЙћга10millionИіЮФМўЃЌ
УЛвЛИіЮФМўЖдгІвЛИіblockЃЌФЧУДОЭНЋвЊЯћКФnamenode 3GЕФФкДцРДБЃДцетаЉblockЕФаХЯЂЁЃШчЙћЙцФЃдйДѓвЛаЉЃЌФЧУДНЋЛсГЌГіЯжНзЖЮМЦЫуЛњгВМўЫљФмТњзуЕФМЋЯоЁЃ
ВЛНіШчДЫЃЌHDFSВЂВЛЪЧЮЊСЫгааЇЕФДІРэДѓСПаЁЮФМўЖјДцдкЕФЁЃЫќжївЊЪЧЮЊСЫСїЪНЕФЗУЮЪДѓЮФМўЖјЩшМЦЕФЁЃЖдаЁЮФМўЕФЖСШЁЭЈГЃЛсдьГЩДѓСПДг
datanodeЕНdatanodeЕФseeksКЭhoppingРДretrieveЮФМўЃЌЖјетбљЪЧЗЧГЃЕФЕЭаЇЕФвЛжжЗУЮЪЗНЪНЁЃ
ДѓСПаЁЮФМўдкmapreduceжаЕФЮЪЬт
Map tasksЭЈГЃЪЧУПДЮДІРэвЛИіblockЕФinput(ФЌШЯЪЙгУFileInputFormat)ЁЃШчЙћЮФМўЗЧГЃЕФаЁЃЌВЂЧвгЕгаДѓСПЕФетжжаЁЮФМўЃЌФЧУДУПвЛИіmap taskЖМНіНіДІРэСЫЗЧГЃаЁЕФinputЪ§ОнЃЌ
ВЂЧвЛсВњЩњДѓСПЕФmap tasksЃЌУПвЛИіmap taskЖМЛсЯћКФвЛЖЈСПЕФbookkeepingЕФзЪдДЁЃБШНЯвЛИі1GBЕФЮФМўЃЌФЌШЯblock sizeЮЊ64MЃЌКЭ1GbЕФЮФМўЃЌУЛвЛИіЮФМў100KBЃЌ
ФЧУДКѓепУЛвЛИіаЁЮФМўЪЙгУвЛИіmap taskЃЌФЧУДjobЕФЪБМфНЋЛсЪЎБЖЩѕжСАйБЖТ§гкЧАепЁЃ
hadoopжагавЛаЉЬиадПЩвдгУРДМѕЧсетжжЮЪЬтЃКПЩвддквЛИіJVMжадЪаэtask reuseЃЌвджЇГждквЛИіJVMжадЫааЖрИіmap taskЃЌвдДЫРДМѕЩйвЛаЉJVMЕФЦєЖЏЯћКФ
(ЭЈЙ§ЩшжУmapred.job.reuse.jvm.num.tasksЪєадЃЌФЌШЯЮЊ1ЃЌЃ1ЮЊЮоЯожЦ)ЁЃСэвЛжжЗНЗЈЮЊЪЙгУMultiFileInputSplitЃЌЫќПЩвдЪЙЕУвЛИіmapжаФмЙЛДІРэЖрИіsplitЁЃ
ЮЊЪВУДЛсВњЩњДѓСПЕФаЁЮФМўЃП
жСЩйгаСНжжЧщПіЯТЛсВњЩњДѓСПЕФаЁЮФМў
1. етаЉаЁЮФМўЖМЪЧвЛИіДѓЕФТпМЮФМўЕФpiecesЁЃгЩгкHDFSНіНідкВЛОУЧАВХИеИежЇГжЖдЮФМўЕФappendЃЌвђДЫвдЧАгУРДЯђunbounde files(Р§ШчlogЮФМў)ЬэМгФкШнЕФЗНЪНЖМЪЧЭЈЙ§НЋетаЉЪ§ОнгУаэЖрchunksЕФЗНЪНаДШыHDFSжаЁЃ
2. ЮФМўБОЩэОЭЪЧКмаЁЁЃР§ШчаэаэЖрЖрЕФаЁЭМЦЌЮФМўЁЃУПвЛИіЭМЦЌЖМЪЧвЛИіЖРСЂЕФЮФМўЁЃВЂЧвУЛгавЛжжКмгааЇЕФЗНЗЈРДНЋетаЉЮФМўКЯВЂЮЊвЛИіДѓЕФЮФМў
етСНжжЧщПіашвЊгаВЛЭЌЕФНтОіЗН ЪНЁЃЖдгкЕквЛжжЧщПіЃЌЮФМўЪЧгЩаэаэЖрЖрЕФrecordsзщГЩЕФЃЌФЧУДПЩвдЭЈЙ§МўаАааЕФЕїгУHDFSЕФsync()ЗНЗЈ(КЭappendЗНЗЈНсКЯЪЙгУ)РДНт ОіЁЃЛђепЃЌПЩвдЭЈЙ§аЉвЛИіГЬађРДзЈУХКЯВЂетаЉаЁЮФМў(see Nathan MarzЁЏs post about a tool called the Consolidator which does exactly this).
ЖдгкЕкЖўжжЧщПіЃЌОЭашвЊФГжжаЮЪНЕФШнЦїРДЭЈЙ§ФГжжЗНЪНРДgroupетаЉfileЁЃhadoopЬсЙЉСЫвЛаЉбЁдёЃК
* HAR files
Hadoop Archives (HAR files)ЪЧдк0.18.0АцБОжав§ШыЕФЃЌЫќЕФГіЯжОЭЪЧЮЊСЫЛКНтДѓСПаЁЮФМўЯћКФnamenodeФкДцЕФЮЪЬтЁЃHARЮФМўЪЧЭЈЙ§дкHDFSЩЯЙЙНЈвЛИіВуДЮЛЏЕФЮФМўЯЕЭГРДЙЄзїЁЃвЛИіHARЮФМўЪЧЭЈЙ§hadoopЕФarchiveУќСюРДДДНЈЃЌЖјетИіУќСюЪЕ МЪЩЯвВЪЧдЫааСЫвЛИіMapReduceШЮЮёРДНЋаЁЮФМўДђАќГЩHARЁЃЖдгкclientЖЫРДЫЕЃЌЪЙгУHARЮФМўУЛгаШЮКЮгАЯьЁЃЫљгаЕФдЪМЮФМўЖМ visible && accessibleЃЈusing har://URLЃЉЁЃЕЋдкHDFSЖЫЫќФкВПЕФЮФМўЪ§МѕЩйСЫЁЃ
ЭЈ Й§HARРДЖСШЁвЛИіЮФМўВЂВЛЛсБШжБНгДгHDFSжаЖСШЁЮФМўИпаЇЃЌЖјЧвЪЕМЪЩЯПЩФмЛЙЛсЩдЮЂЕЭаЇвЛЕуЃЌвђЮЊЖдУПвЛИіHARЮФМўЕФЗУЮЪЖМашвЊЭъГЩСНВуindex ЮФМўЕФЖСШЁКЭЮФМўБОЩэЪ§ОнЕФЖСШЁ(МћЩЯЭМ)ЁЃВЂЧвОЁЙмHARЮФМўПЩвдБЛгУРДзїЮЊMapReduce jobЕФinputЃЌЕЋЪЧВЂУЛгаЬиЪтЕФЗНЗЈРДЪЙmapsНЋHARЮФМўжаДђАќЕФЮФМўЕБзївЛИіHDFSЮФМўДІРэЁЃ ПЩвдПМТЧЭЈЙ§ДДНЈвЛжжinput formatЃЌРћгУHARЮФМўЕФгХЪЦРДЬсИпMapReduceЕФаЇТЪЃЌЕЋЪЧФПЧАЛЙУЛгаШЫзїетжжinput formatЁЃ ашвЊзЂвтЕФЪЧЃКMultiFileInputSplitЃЌМДЪЙдкHADOOP-4565ЕФИФНј(choose files in a split that are node local)ЃЌЕЋЪМжеЛЙЪЧашвЊseek per small fileЁЃ
* Sequence Files
ЭЈ ГЃЖдгкЁАthe small files problemЁБЕФЛигІЛсЪЧЃКЪЙгУSequenceFileЁЃетжжЗНЗЈЪЧЫЕЃЌЪЙгУfilenameзїЮЊkeyЃЌВЂЧвfile contentsзїЮЊvalueЁЃЪЕМљжаетжжЗНЪНЗЧГЃЙмгУЁЃЛиЕН10000Иі100KBЕФЮФМўЃЌПЩвдаДвЛИіГЬађРДНЋетаЉаЁЮФМўаДШыЕНвЛИіЕЅЖРЕФ SequenceFileжаШЅЃЌШЛКѓОЭПЩвддквЛИіstreaming fashion(directly or using mapreduce)жаРДЪЙгУетИіsequenceFileЁЃВЛНіШчДЫЃЌSequenceFilesвВЪЧsplittableЕФЃЌЫљвдmapreduce ПЩвдbreak them into chunksЃЌВЂЧвЗжБ№ЕФБЛЖРСЂЕФДІРэЁЃКЭHARВЛЭЌЕФЪЧЃЌетжжЗНЪНЛЙжЇГжбЙЫѕЁЃblockЕФбЙЫѕдкаэЖрЧщПіЯТЖМЪЧзюКУЕФбЁдёЃЌвђЮЊЫќНЋЖрИі recordsбЙЫѕЕНвЛЦ№ЃЌЖјВЛЪЧвЛИіrecordвЛИібЙЫѕЁЃ
НЋвбгаЕФаэЖраЁЮФМўзЊЛЛГЩвЛИіSequenceFilesПЩФмЛсБШНЯТ§ЁЃЕЋ ЪЧЃЌЭъШЋгаПЩФмЭЈЙ§ВЂааЕФЗНЪНРДДДНЈвЛИівЛЯЕСаЕФSequenceFilesЁЃ(Stuart Sierra has written a very useful post about converting a tar file into a SequenceFile ЁЊ tools like this are very useful).ИќНјвЛВНЃЌШчЙћгаПЩФмзюКУЩшМЦздМКЕФЪ§ОнpipelineРДНЋЪ§ОнжБНгаДШывЛИіSequenceFileЁЃ
 ЯВЛЖ
ЯВЛЖ  ЖЅ
ЖЅ ФбЙ§
ФбЙ§ х
х ЮЇЙл
ЮЇЙл ЮоСФ
ЮоСФ